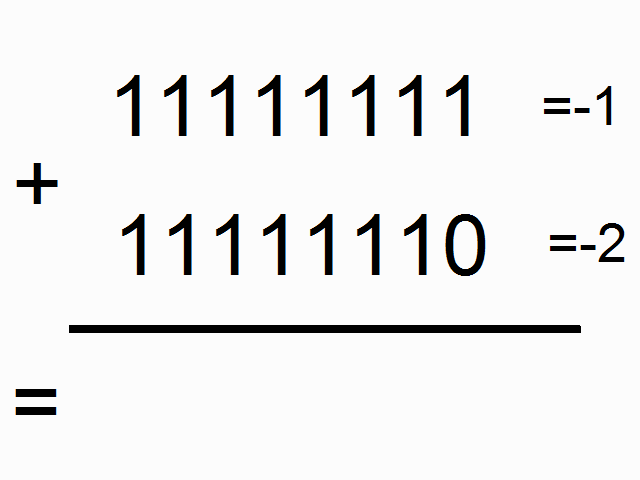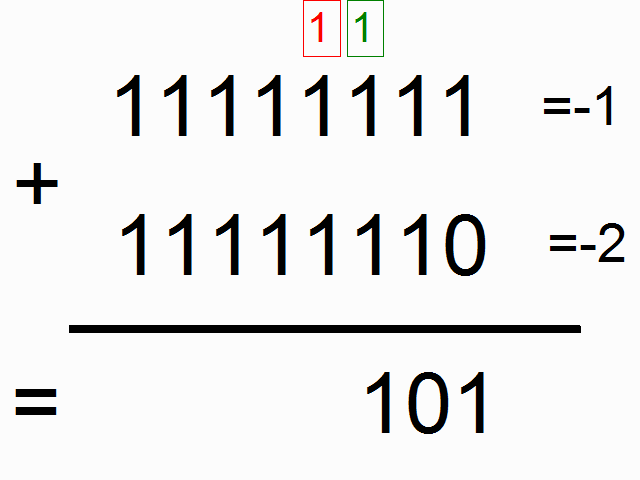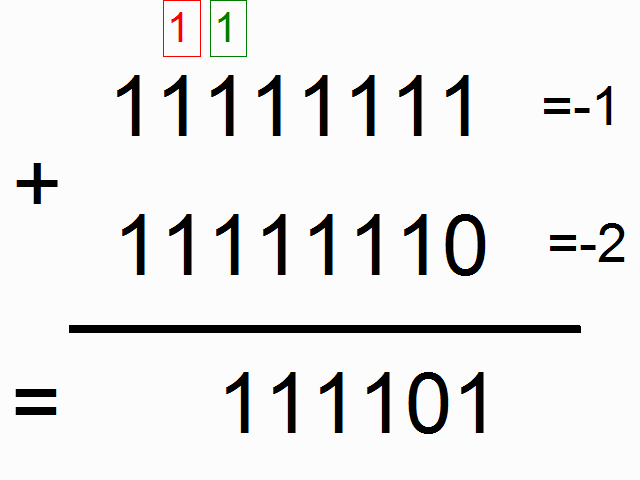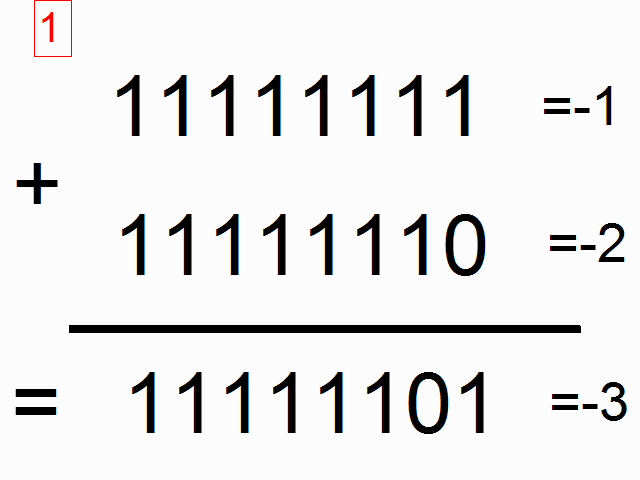When a ball put inside a box has a longer diameter than the box
I had a chance to read Ferenc's interesting post about counter-intuitive things happening in a high dimensional space. This reminds me a very simple but another interesting example I met in a topology class.
I found this example in a series of YouTube lectures about topology and geometry by professor Tadashi Tokieda. This example is very easy to understand with a simple logic though it triggers a lot of interesting thoughts and broadens my sight. I hope this would also help the readers to glimpse a deep and extraordinary world of a high dimensional space.
To start, let's begin with an easy example of 2D space. Think about the situation that you put every corner of the square (each side has a length of one, $I^2$ with a white disk. Then, try to fit a red disk in the middle.
2D square example
Then, what is the diameter of the red disk? You can solve this problem in various ways but let me introduce a very intuitive and simple way.
Solution
As you can see in the above picture, you would immediately notice that the length of the diagonal line is equal to the sum of two white disks' and two red disks' diameters. Therefore, you can derive the diameter of the red ball $d_{red}$ as below:
$$d_{red} = \frac{\sqrt{2}-1}{2}.$$
Since the value of $\sqrt{2}$ is approximately 1.414, the diameter of the red disk is approximately 0.2, which is definitely smaller than the length of each side of the square. This simply means that this disk in the middle is smaller than the square. Well... Of course! Because we put it in the square.
What would happen when we go to 3D box $I^3$?
3D box example
Again, it is not hard to find $d_{red}$. In an analogous way with the previous solution, we can simply find the fact that the length of the diagonal line of the box would be also same with the sum of two white balls' and red balls' diameters.
By the Pythagorean theorem, we can easily derive the diameter of the red ball by
$$d_{red} = \frac{\sqrt{3}-1}{2}\approx 0.35 <1.$$
It is still smaller than the box though it has increased a little.
Let's do the same in $I^m$. Still the length of the diagonal line across the high dimensional box would be found by the square root of the sum of the squares of all the sides it has.
Therefore, the general solution for $d_{red}$ in $m$-th dimension can be derived as follows:
$$d_{red} = \frac{\sqrt{m}-1}{2}.$$
You may already notice that this will give a very interesting result when $m\geq 9$. Whenever $m$ goes beyond 10, we would find the ball which is put inside the box would have longer diameter than the length of each side of the box!
"When a ball put inside a box has a longer diameter than the box's side!"
This simple but very counter-intuitive example shows how much our intuition can be wrong when it comes to a high dimensional space. As written in the front desk of my blog, I always try to think in pictures and visualize more when I meet a new concept. However, this example always rings me a warning that I have to be very careful whenever I cross the line above three-dimensional space.
I hope the readers would also find the fresh impression that I felt when I met this example for the first time. Thank you for your reading and please leave the comments if you liked it.
먼저 쉬운 예부터 시작하기 위해서, 각 변의 길이가 1인 2D 사각형 $I^2$ 안에 네 귀퉁이마다 흰 공을 넣고 맨 중간에 남는 공간에 빨간 공을 채운다고 해보자.
2차원 박스 예시
이 때, 이 공의 지름은 어떻게 되는지 생각해보자. 다양한 방법으로 이를 구할 수 있겠지만 매우 직관적이고 깔끔한 방법 하나를 소개해보면 다음과 같다.
풀이
이렇게 여러 사각형을 붙여보면 대각선의 길이는 빨간 공 두 개와 흰 공 두 개의 지름을 합한 것과 같고, 흰 공 두 개의 지름의 합은 1이기 때문에 아래 수식으로 빨간 공의 지름 $d_{red}$를 쉽게 구할 수 있다:
$$d_{red} = \frac{\sqrt{2}-1}{2}.$$
$\sqrt{2}$의 값은 대략 1.414이므로 빨간 공의 지름은 대략 0.2이고 박스의 크기인 1보다 작다. 뭐, 당연한 일이다. 애초에 박스 안에 공을 넣었는데 박스보다 공이 클 수가 있겠는가?
자, 조금 더 확장해서 3차원 박스 $I^3$가 되면 어떨까?
3차원 박스 예시
이 때의 $d_{red}$ 역시도 그리 어렵지 않다. 앞서 소개한 방식으로 생각을 조금만 더 확장하면, 박스를 가로지르는 빗변의 길이가 흰 공 두 개와 빨간 공 두 개의 지름의 합과 같다는 것은 여전히 유효하다는 것을 알 수 있다. 따라서 피타고라스 정리를 생각하면 아래 사각형의 변들의 제곱과 높이의 제곱을 모두 더한 것에 루트를 씌워 쉽게 구할 수 있다:
$$d_{red} = \frac{\sqrt{3}-1}{2}\approx 0.35 <1.$$
이 역시도 여전히 박스 한 변의 길이인 1보다는 작다. 그런데 여기서 재미있는 점은 빨간 공의 지름이 조금 커졌다는 것이다.
이를 임의의 $m$ 차원으로 확장하면 어떻게 될까? $m$ 차원 박스 $I^m$을 가로지르는 빗변의 길이는 피타고라스의 정리에 의해 모든 변의 제곱의 합에 루트를 씌운 것과 같다.
그러면 위에 공식에 따라 $m$ 차원 구 $d_{red}$에 대한 일반 해를 다음과 같이 정리할 수 있는데:
$$d_{red} = \frac{\sqrt{m}-1}{2}.$$
눈치 빠른 분들은 이미 아셨겠지만, $m\geq 9$가 되는 순간 빨간 공의 지름이 박스 한 변의 길이인 1보다 크거나 같아지게 된다. 즉, 우리는 분명 박스 안 모든 귀퉁이에 흰 공들을 넣고 그 안 쪽 공간에 빨간 공을 우겨 넣었지만 빨간 공의 지름은 박스보다 크다!
"박스 안에 넣은 공의 지름이 박스보다 크다!"
매우 단순하고 쉽지만 고차원으로 넘어갈 때, 우리의 직관이 얼마나 틀릴 수 있는지 보여주는 좋은 예시라고 생각한다. 블로그 인사글과 같이 언제나 그림으로 상상하는 것을 즐기고 그렇게 할 수 있을 때, 가장 강력한 직관과 이해를 얻을 수 있다고 생각하지만 (Think in Pictures and Visualize More!) 고차원으로 갈 때는 이런 재미있는 일들이 자주 일어나기 때문에 매우 조심해야한다는 것도 염두에 두어야하겠다.
처음 이 예시를 접했을 때 느꼈던 신선함을 다른 분들도 느끼길 바라며 초짜 공돌이의 짧은 위상 수학 산책을 마친다.
이번 CVPR 2017에 Accept 되었다는 Learning by Association 논문을 리뷰해보겠습니다. 짧은데 재미있는 논문이에요.
아이디어는 상당히 직관적이고 간단합니다. 구글에 "Learning by Association"이라고 검색하면 가장 먼저 뜨는 것은 사실 인지 심리학 쪽의 자료들입니다. 저자들도 사람이 "Association"을 사용하여 학습을 한다는 내용에서 착안했다고 하는군요.
이게 무슨 말이냐 하면, 사람은 기계와는 달리 자료 간의 "연관성"을 파악하여 학습할 수 있기 때문에 매우 많은 예제를 보지 않더라도 학습을 잘 할 수 있다는 것입니다.
Learning by Association 예시 ([2],[3])
즉, 아이가 처음 "개"라는 것을 알게될 때 몇 가지 예시를 보고 나면, 후에 진돗개를 처음 보더라도 연관성을 바탕으로 유추를 하여 "개"라는 것을 자연스럽게 안다는 것이죠.
그렇다면 이런 "연관성"을 기계학습에도 가져와서 사용할 수는 없을까?라는 것이 이 논문의 주된 아이디어입니다. 만약 이런 학습이 가능하다면 label을 얻는 것이 매우 비싸거나 (의료 영상 데이터) 아주 적은 양만 label이 있는 데이터에도 학습을 잘 할 수 있겠죠. 즉 이 논문의 주안점은 semi-supervised learning을 좀 더 잘 해보자는 것입니다.
Overview
자 그러면 이렇게 추상적인 개념인 "연관성"을 어떻게 기계학습에 적용을 했는지 살펴볼까요? 먼저 이 논문에서 설정한 가정 하나를 보겠습니다.
"네트워크가 embedding feature vector를 제대로 만들어낸다면, 동일 클래스의 경우 feature space에서 vector간 서로 비슷하게 생겼을 것이다."
좀 너무 당연한가요? 그래도 이 당연한 가정에서 문제를 푸는 전략이 나옵니다. Loss 함수를 잘 디자인해서 labeled와 unlabeled data가 embedding feature space에서 서로 비슷한 녀석들끼리 가깝고 다른 녀석들끼리는 거리가 멀도록 하는 네트워크를 만드는 것이 목표입니다.
그러면 자연스럽게 embedding space에서 각각의 data 사이에 가깝다 멀다를 어떻게 정의해야할지에 대한 질문이 생깁니다. 이 논문에서는 이를 다음과 같이 정의했는데요.
각각, $A$: Labeled data, $B$: Unlabeled data의 feature space vector를 나타낼 때, $A_i$와 $B_j$ 사이의 유사도 $M){ij}$는 다음과 같이 내적 (inner product)로 정의합니다:
$$M_{ij}=A_i\cdot B_j$$ 여기까지만 보면 기존의 semi-supervised learning과 전혀 다를 것이 없지만, 앞으로 소개할 "연관성"이란 개념을 넣어 학습시키는 부분을 보시면 차이를 아실 수 있을 것 같습니다.
여기서부터가 중요합니다. 데이터가 들어왔을 때 embedding을 해주는 네트워크(초록색)가 있으면, 이로부터 feature space가 만들어지죠. 이런 embedding space에서 labeled data와 unlabeled 사이에 "연관성"을 정량화하기 위해 이 논문에서는 "walking"이라는 방법을 사용합니다.
위에 그림에서 보실 수 있듯이 labeled data의 feature vector에서 unlabeled data의 feature vector로 갔다(visit)가 다시 labeled data의 feature vector로 돌아왔을 때(walk) labeled data의 class가 바뀌지 않도록 제약을 주는 방식으로 loss 함수를 디자인합니다. 이 얘기들을 좀 더 수식화하여 나타내면 다음과 같습니다:
총 세 부분으로 loss 함수가 나누어져있는 것을 알 수 있는데요 사실 이를 $\cal{L}_{walker}+\cal{L}_{visit}$와 $\cal{L}_{classification}$ 이렇게 두 부분으로 묶어 보시면 좀 더 이해가 편합니다.
앞의 $\cal{L}_{walker}+\cal{L}_{visit}$ 부분이 오늘 소개할 association을 표현하는 loss 함수에 해당하구요 뒤의 $\cal{L}_{classification}$ 부분이 일반적으로 지도학습에서 사용하는 classfication loss가 되겠습니다. Label이 있는 녀석들에 대해서는 이런 loss 함수가 적용이 됩니다. (제가 예전에 정리해둔 DANN을 보신 분들이라면 좀 더 이해가 쉬울 수 있습니다.)
그래서 (아직까지는 어떻게 만들었는지는 모르지만) loss 함수를 잘 minimize하면 마법처럼 unlabeled data도 labeled data와 함께 잘 분류가 되게 하자는 것입니다. 그럼 하나하나 loss 함수를 이해해보겠습니다.
Walker loss
먼저 $\cal{L}_{walker}$입니다. 여기서 walk라는 이름은 제가 짐작하기로는 graph theory 쪽 용어를 가져온 것 같습니다. Graph theory 쪽 공부를 하다보면 data 하나를 점으로 보았을 때, 한 점에서 다른 점으로 가는 것을 "walk"라는 용어로 표현합니다.
위 그림이 walker loss에서 하고자 하는 일을 잘 설명해주고 있습니다. Labeled data의 class인 "개"에서 unlabeled loss를 방문한 후 다시 Labeled data로 돌아갔을 때 class가 여전히 "개"로 유지되길 바라는 것입니다. 여기서 주의하실 점은 돌아온 labeled data가 꼭 시작점의 labeled data와 정확히 일치할 필요는 없지만, class는 유지되기를 바라는 것입니다.
그래서 $\cal{L}_{walker}$에서는 만약 갔다가 돌아온 class가 달라지면 penalty를 주게 디자인 되어있습니다:$$\cal{L}_{walker}:=H(T,P^{aba})$$
여기서 $H$는 cross entropy이고 $T_{ij}$는 $class(A_i)=class(A_j)$일 때, $1/\#class(A_i)$이고 아닐 때는 0인 uniform distribution입니다. $P^{aba}$가 닮기를 바라는 $T$가 uniform distribution인 이유는 동일한 class로만 돌아오면 언제나 값이 같도록 하고 싶기 때문이죠. (동일한 class의 다른 이미지로 돌아왔다고 penalty를 주고 싶지 않을 것입니다.)
Visit loss
이제 visit loss입니다.
$$\cal{L}_{visit}:=H(V,P^{visit})$$
where, $ P_j^{visit} :=<P_{ij}^{ab}>_i, V:=1/|B|$
이 녀석이 하고자 하는 것도 그리 어렵지 않습니다 최대한 많은 sample을 다 골고루 봤으면 좋겠다는 것이죠. 대부분의 semi-supervised 방식에서는 자기가 고른 labeled data를 기준으로 가까이에 있는 unlabeled data만 보는데 그러지 말고 모두 다 보자는 것입니다. (그래서 $V$가 uniform distriction이지요. 그림을 통해보면 다음과 같습니다:
즉, 그림의 중간 동그라미 안에 들어가 있는 녀석들처럼 애매한 부분도 효과적으로 활용하고 싶다는 것이죠. 단, 여기서 unlabeled data가 너무 다른 경우 이 visit loss가 악영향을 끼치기 때문에 적절히 weight를 주는 것이 필요하다고 하네요.
실험 결과
MNIST
실험 결과도 상당히 놀랍습니다. 먼저 MNIST 결과에 대해서 학습 전후로 association이 어떻게 바뀌어 가는지 시각화해서 보여주면 다음과 같습니다:
Evolution of Associations
Top 부분이 학습을 시작해서 아주 약간 iteration을 돌렸을 때고 Bottom이 네트워크가 수렴한 후를 의미합니다.
이 실험 이후 MNIST에서 분류가 얼마나 잘 되었는지 확인을 해보면, test error가 0.96%로 매우 낮게 나왔는데요. 심지어 이렇게 틀린 경우도 설명이 가능하다고 얘기합니다. 우측에서 보이는 것이 confusion matrix인데요 여기서 틀린 부분을 좌하단에서 가져와 보여주면 사람이 봐도 왜 틀렸는지 이해가 갈만한 비슷비슷한 숫자들을 헷갈린 것이라고 애기하고 있습니다.
STL-10
저는 개인적으로 이 실험 결과가 매우 흥미롭습니다. STL-10은 RGB 이미지로 10개의 class가 있는 데이터셋인데요 약 5000개의 labeled 학습 이미지와 10만개의 unlabeled 학습 이미지가 있습니다. 재미있는 점은 이 unlabeled 이미지에 labeled 학습 이미지에 존재하지 않는 class의 이미지들도 있다는 것이죠.
그래서 결과를 보시면 매우 신기합니다. 위 두 줄이 labeled 이미지에 class가 있는 녀석의 nearest neighbor를 5개 뽑아본 것으로 상당히 잘 되는 것을 보실 수 있죠. 아래 두 줄이 제가 흥미롭게 생각한 부분입니다. Labeled 이미지 데이터셋에 존재하지 않는 class인 돌고래와 미어켓을 보여주니 네트워크가 내놓은 5개의 nearest neighbor인데요. 나름 비슷합니다. 돌고래의 삼각 지느러미 부분이 돛이나 비행기의 날개와 비슷하다 생각했는지 그런 이미지들이 같이 있고 미어켓은 신기하게도 동물들을 뽑아 온 것을 보실 수 있죠.
SVHN
이어서 SVHN에 대해 적용한 결과도 보여줍니다.
이 테이블이 보여주는 점은 자신들의 method가 unlabeled 데이터셋이 점점 많이 주어질 수록 에러율이 매우 내려간다는 것입니다. 즉, unlabeled 데이터로부터 실제로 연관 정보를 잘 뽑아내고 있다는 것이죠.
더욱 놀라운 점은 SVHN 데이터로 MNIST 데이터에 대한 Domain Adaptation 효과를 보여준 것입니다. 아래 테이블을 보시면 각각 SVHN에서만 학습시켰을 때, SVHN에서 학습시킨 후 MNIST로 Domain Adaptation 시켜줬을 때, MNIST에서만 학습시켰을 때, 세 가지 경우에서 MNIST 데이터셋에 대한 classification error를 알 수 있습니다.
이를 자신들의 method와 Domain Adaptation에서 최근 유명했던 DANN, Domain Separation Nets 두 가지와 성능을 비교했는데 상당히 잘 되는 것을 볼 수 있습니다.
Summary
지금까지 쭉 빠르게 논문을 살펴보았는데요 이 논문의 contibution을 정리해보자면 다음과 같습니다:
단순하지만 신선한 semi-supervised training method를 제안하였다.
Tensorflow implentation이 있고 arbitray network architecture에 add-on처럼 범용적으로 붙여 사용할 수 있다.
SOTA methods에 비해 최대 64% 가까이의 성능 향상을 보였다.
Label이 매우 적을 때, SOTA methods를 매우 큰 차이로 이기는 결과를 확인하였다 (MNIST, SVHN)
게다가 심지어 ResNet 같은 복잡한 구조를 사용한 것도 아닌데 이런 결과가 나왔다는 것을 보면, 아직 성능이 더 개선이 될 여지가 충분하다는 것도 짚고 넘어가야할 것 같네요
이 논문을 읽고 아이디어가 새록새록 생기는데...일단 이 아이디어들은 나중에 졸업부터 하고 해야겠죠...지금 제 코가 석자라 ㅎㅎ 그래도 정말 재미있게 읽은 논문이었습니다.
자 오늘은 f-GAN의 main theorem을 증명하고 저자가 NIPS 2016 workshop에서 발표할 때 전해줬던 insight 하나를 소개하는 것으로 f-GAN에 대한 설명을 마무리하겠습니다. 먼저 설명의 편의를 위해 오늘 증명할 Theorem 1과 그 조건을 다시 가져와보겠습니다.
지난 글에서 f-GAN 저자들이 Single-Step 알고리즘을 제안하였던 것을 기억하실겁니다:
우리가 풀고자 하는 GAN objective 함수 $F$에 대하여, 우리가 찾고 싶은 saddle point의 근방(neighborhood)에서 $F$가 strongly convex in $\theta$ 그리고 strongly concave in $w$일 때, 이 알고리즘이 실제로 그 saddle point $(\theta^t,w^t)$에 수렴한다는 것을 확인해보겠습니다. 이 조건들을 수식으로 나타내면 다음과 같습니다:
\begin{equation}\nabla_\theta F(\theta*,w*)=0, \nabla_w F(\theta*,w*)=0, \nabla^2_\theta F(\theta,w) \succeq \delta I, \nabla^2_w F(\theta,w)\preceq -\delta I.\label{cond}\end{equation}
이 가정들은 "strong"하다는 부분만 빼면 f-GAN 형태로 도출된 saddle point를 정의하기 위해서 필수적인 조건들입니다. 따라서 deep networks의 구조로 인해 생기는 수많은 saddle point들이 있습니다만 대부분이 이 조건을 만족하지 않습니다.
저는 이 부분을 GAN이 원하는 saddle point가 독특하고 GAN objective를 알고리즘을 적용하여 풀어서 나오는 solution들은 이러한 조건을 만족하는 point로 수렴한다는 것을 말하고자한 것으로 해석했습니다.
이제 이 조건이 성립한다는 가정하에 다음 정리가 성립하게 됩니다.
Suppose that there is a saddle point $\pi^*=(\theta^t,w^t)$ with a neighborhood that satisfies conditions \ref{cond}. Moreover, we define $J(\pi)=\frac{1}{2}||\nabla F(\pi)||^2_2$ and assume that in the above neighborhood, $F$ is sufficiently smooth so that there is a constant $L>0$ such that $||\nabla J(\pi')-\nabla J(\pi)||_2 \leq L||\pi'-\pi||_2$ for any $\pi,\pi'$ in the neighborhood of $\pi^*$. Then using the step-size $\eta=\delta/L$ in Algorithm 1, we have
$$J(\pi^t)\leq \left(1-\frac{\delta^2}{2L}\right)^t J(\pi^0).$$
That is, the squared norm of the gradient $\nabla F(\pi)$ decreases geometrically.
(우와 어려워보인다...) 아닙니다! 생각보다 쉬워요!
본격적인 증명에 앞서 이 복잡해보이는 정리가 의미하는 바를 좀 정리해보겠습니다. 이 정리는 알고리즘의 "local" convergence를 증명해주고 있습니다.
$J(\pi) \overset{\Delta}{=}\frac{1}{2}||\nabla F(\pi)||^2_2$로 정의한 것을 곰곰히 생각해보면 됩니다. 결국 이 정리에서 결론으로 내리는 부등호가 하고자 하는 말은 우리가 구하고자 하는 GAN objective $F$의 gradient인 $\nabla F(\pi)$의 크기가 점차점차 줄어든다는 것입니다. 즉, 수렴한다는 것이죠.
"어때요 참 쉽죠?"
다만, 우리가 saddle point의 근방에 있다면 언제나 saddle point로 수렴한다는 것을 증명한 것이지 global convergence를 증명해주진 못했습니다. 그러면 자연스럽게 떠오르는 의문이 있죠? "어떻게 그 근방에 갈껀데?" 네...그건 뭐 저자들도 "일단 practically 잘 되니까 쓰자"고 하네요 -_-ㅎㅎ (이전 글에서 두 가지 예를 보여드렸었죠?)
먼저 몇 가지 notation을 정하고 가겠습니다. 편의상 $\pi=(\theta^t,w^t)$라 정의하고 각각의 편미분을 다음과 같이 나타내겠습니다:
$$\nabla F(\pi) = \begin{pmatrix} \nabla_\theta F(\theta,w) \\ \nabla_w F(\theta,w) \end{pmatrix}, \tilde{\nabla} F(\pi) = \begin{pmatrix} -\nabla_\theta F(\theta,w) \\ \nabla_w F(\theta,w) \end{pmatrix}.$$
그러면 Algorithm 1은 다음과 같이 쓸 수 있게 됩니다:
\begin{equation}\pi^{t+1} = \pi^t + \eta \tilde{\nabla} F(\pi^t)\label{eq2}\end{equation}
이제 본격적으로 증명을 시작해보겠습니다. 기본적으로 증명에 쓰이는 가장 어려운 수준의 수학은 Taylor series 전개입니다. Taylor series를 이용하면,
\begin{equation}J(\pi')\approx J(\pi)+<\nabla J(\pi),\pi'-\pi>+\frac{1}{2}(\pi'-\pi)^T H(J(\pi))(\pi'-\pi). \label{eq3}\end{equation}
여기서 $H$는 Hessian matrix를 뜻합니다. 주어진 조건을 바탕으로 다음과 같은 부등호를 얻을 수 있고:
$$||\nabla J(\pi')-\nabla J(\pi)||_2 \leq L||\pi'-\pi||_2 $$
$$\lim_{\pi'\rightarrow \pi}\frac{||\nabla J(\pi')-\nabla J(\pi)||_2}{||\pi'-\pi||_2} \leq L $$
\begin{equation}\therefore H(J(\pi)) \leq L \label{eq4}\end{equation}
이렇게 얻은 부등호 eq.\ref{eq4}을 eq.\ref{eq3}에 적용하면,
\begin{equation}J(\pi')\leq J(\pi)+<\nabla J(\pi),\pi'-\pi>+\frac{L}{2}(\pi'-\pi)^T (\pi'-\pi). \label{eq5}\end{equation}
여기서 $J(\pi) \overset{\Delta}{=}\frac{1}{2}||\nabla F(\pi)||^2_2$이므로, $\nabla J(\pi)=\nabla^2 F(\pi)\nabla F(\pi)$입니다.
따라서, 다음과 같은 전개가 가능해집니다:
자, 이걸 곰곰히 생각해보시면 Algorithm 1이 해주는 일이란 것이 결국 $||\nabla F(\pi)||_2^2$에 비례하는 양으로 $J$를 줄여주고 있는 것이란 것을 아실 수 있습니다.
안 되요 안 되요! 정신줄 놓아버리시면 안 됩니다!! ㅋㅋ 뜬금없이 뭔소리냐 위에 부등식은 왜 갑자기 푸는가?가 궁금하시죠? Eq.\ref{eq2}와 eq.\ref{eq3}를 조금만 바꾸면 아래 과정을 왜 하는지 이해할 수 있습니다.
Algorithm 1이 eq. \ref{eq2}로 나타내진다고 했었죠? 이를 $\pi^{t+1} - \pi^t = \eta \tilde{\nabla} F(\pi^t)$로 조금만 바꾸고 eq.\ref{eq3}에 대입하면 이 짓을 왜 하는지 이해하실 수 있습니다:
자, 이렇게 하고 나니 아래의 수식 전개에서 두번째 부등호가 위에서 구한 부등호 때문이란 것을 알 수 있게 되는 것입니다:
여기서 마지막 equality는 $\eta = \delta/L$일 때 성립합니다. 그래서 step size $\eta$를 이렇게 정하면 위 부등식에 의해 local convergence가 보장되는 것이죠.
드디어 증명이 끝났군요 (에고 힘들다).
Discussion
그래요 이제 증명도 되었고 (local이긴 하지만), 여러가지 함수로 divergence를 바꿔가며 GAN을 해보면 그 때마다 새로운 녀석이 나올 것이고, 수학적으로는 어떤 divergence가 어떤 녀석보다 더 나은지 등등이 연구가 되어있기 때문에 이제 내 상황에서 가장 적절한 f-divergence를 만들어서 쓰기만 하면 될 것 같습니다.
그런데...대다수의 divergence가 잘 동작하긴 하는데....결과를 일단 먼저 보여드리자면:
(* LSUN dataset의 classroom에 대해서 학습을 시킨 것이고 각각 Jensen-Shannon, Hellinger, Kullback-Leibler divergence를 사용한 결과입니다)
GAN (Jensen-Shannon)
Hellinger
Kullback-Leibler
생각보다 결과가 그놈이 그놈이더라...하는 것입니다.
왜?!! 어째서?!!!
Insights from the Authors
자연스래 아래와 같은 질문이 나올 수 밖에 없죠.
"Does the divergence REALLY matter?"
그래서 저자가 한 가지 추측을 내놓는데 다음과 같습니다:
각각의 색으로 나타낸 점이 서로 다른 divergence로 학습한 수렴점이라고 생각하시면 됩니다. 이와 같이 우리가 세운 모델의 공간과 실제 확률 분포 $P$가 이렇게 꽤나 가까이에 있을 때는 divergence 간에 수렴점이 차이가 있습니다. 그런데 이게 아니라 다음과 같이 멀리 떨어져 있다고 해봅시다:
이러면 마치 태양에서 오는 빛은 직선이라고 생각할 수 있듯이 divergence 간에 차이가 매우 적어집니다. 즉, 저자들은 우리의 모델이 생각보다 실제 분포와 매우 멀리 떨어져 있는 것이 아닌가 하는 추측을 내놓는 것입니다.
매우 직관적이고 그럴 듯하죠? 이에 대한 토론이 NIPS 2016 Workshop 영상에서 보이듯이 발표 이후로도 이어졌습니다. 실제도 이런 추측이 최근 GAN에 대한 연구 결과들과도 어느 정도 부합하는 것 같습니다.
이로써 f-GAN에 대한 설명을 모두 마쳤네요. 슬슬 그래도 제가 생각한 골격을 하나하나 따라 올라가고 있습니다. 다음은 EBGAN을 리뷰할 생각입니다. EBGAN까지 하면 어느 정도 제가 구상했던 커다란 틀이 80% 정도는 완성되는 것입니다. 참 오래 걸리네요. 역시 이론 위주의 논문은 글을 쓰기가 힘듭니다. 수식도 많고...-_-;; 아무쪼록 이 글이 읽는 분들께도 많은 도움이 되었길 기대합니다. 다음 글에서 뵙겠습니다.
여전히 매주 일요일마다 12명이 돌아가며 두 명씩 두 편의 논문을 40분 동안 발표하고 있습니다. 벌써 한 번 순서가 다 돌아서 다시 제 차례가 되어 이번에는 GAN과도 관련이 있지만 또 다른 커다란 분야인 Domain Adaptation 연구를 소개하였습니다. 아직도 이런 경험이 부족하고 전달하고픈 내용은 많고 하필 논문에는 수식이 많아 발표 시간이 부족하네요. 그래도 이번에는 끝까지 다 발표를 마쳤습니다.
지난 글에서 f-divergence를 estimate하기 위해 시작한 전개로부터 일반적인 GAN objective까지 전개하는 것을 따라가 보았습니다. 이제는 이를 풀 알고리즘과 convergence를 증명하는 부분이 남았는데요. 본격적으로 들어가기 전에 지난 내용을 리뷰하고 GAN formulation과의 관계에 대해 약간 더 구체적으로 이해하기 위해 조금 더 설명을 해보도록 하겠습니다.
먼저 설명의 편의를 위해 지난 글에서 전개했던 variational representation을 가져오면 다음과 같고:
여기서 우리는 맨 마지막 식을 사용하여 true distribution $P$를 generative model $Q$로 estimate할 것입니다.
오랜만에 다시 GAN으로 돌아와서 포스팅을 해봅니다. 요즘은 너무 GAN쪽 연구가 많이 그리고 빨리 발전하고 있어서 글을 리뷰하는 것이 민망할 지경입니다. 심지어 응용뿐 아니라 이론적인 부분에서도 꽤나 많은 부분이 연구되고 바뀌고 있기에 따라가기가 벅찹니다.
이 논문만 해도 작년 6월 arXiv에 올라왔고 NIPS 2016 워크샵에서 발표하는 것을 직접 들었었는데 이게 한~~~~~~참 전 논문으로 취급되고 있는 것을 보면 머신러닝 분야는 참 짧은 시간에 격세지감 느끼기 좋은 분야인 것 같습니다...orz
WGAN 이전에는 f-GAN 논문이 다른 연구들을 모조리 잡아먹는? 느낌을 주었으나 이제는 이 말도 무색할 지경입니다. 그래도 f-GAN 논문은 여러모로 GAN 분야에서 매우 중요한 milestone이기 때문에 사실 다른 것보다 더 먼저 리뷰했어야 하는데 여러 이유로 블로그 글로 정리하지 못해서 항상 마음에 걸렸습니다.
아무튼 이 논문이 마치 어제 나온 것인양! 한 문장으로 요약해보자면 다음과 같습니다:
"앞으로 너희가 어떤 divergence를 사용해서 GAN을 구성하든지 모두 다 나의 하위 호환(special case)일 따름이다."
...패기롭다....ㅋㅋ
이 때만 해도 vanilla GAN objective가 JSD를 이용해서 $p_{model}$과 $p_{data}$의 차이를 계산하는 것이란 분석을 바탕으로, 조금씩 네트워크의 구조를 바꾸거나 regularization term을 새로 붙여본다거나 하는 등 약간의 변화만 주고 있던 때라는 점을 생각해보시면...
이렇게 근간을 쥐고 흔드는 내용을 NIPS 2016 워크샵에서 얘기해줄 때 이제 막 혹시 다른 divergence는 어떨까 하면서 새로운 GAN 형태를 연구해보던 사람들은 어떤 느낌이었을까요? 저는 그 때서야 갓 GAN을 접하던 시기(사실 처음 그곳에서 GAN이란 게 있단 것을 알았습니다ㅎㅎ)라 잘 못 느꼈습니다만 기존에 연구를 하던 사람들에게는 꽤나 충격적이었을 것으로 보입니다.
지난 시간에 $\tilde{\nabla}f(w_k):=\nabla f(w_k;x_{i_k})$가 data batch $x_{i_k}$에 대한 loss function $f$의 gradient일 때, non-adaptive, adaptive methods들을 다음과 같이 일반화했었습니다:
\begin{equation*}w_{k+1}=w_k-\alpha_kH_k^{-1}\tilde{\nabla}f(w_k+\gamma_k(w_k-w_{k-1}))+ \beta_kH_k^{-1}H_{k-1}(w_k-w_{k-1}).\end{equation*}
이 때, $H_k:=H(w_1,\cdots,w_l)$는 positive definite matrix이며, 필수적인 것은 아니지만 문제를 좀 단순화하기 위해 $H_k$를 다음과 같이 놓습니다: $$H_k=diag\left(\left\{\sum_{i=1}^k\eta_ig_i\circ g_i\right\}^{1/2}\right).$$ 여기서 $\circ$는 Hadamard product이고 $g_k=\tilde{\nabla}f(w_k+\gamma(w_k-w_{k-1}))$이며, $\eta_k$는 각 알고리즘마다 특화된 coefficients set이라고 생각하시면 됩니다.
Preconditioning의 문제점
이 논문에서는 AdaGrad, RMSProp, Adam 등의 adaptive methods가 사용하는 여러 방식의 변주들을 preconditioning이라는 단어로 묶어서 표현합니다.
Non-adaptive methods와 비교할 때 multiple global minima를 갖는 문제에서 adaptive methods는 알고리즘에 따라 서로 완전히 다른 해들이 나올 수 있다는 것을 보여주는데요. 이 때 보다 간단히 문제를 이해하기 위해 다음과 같은 binary least-square classification 문제로 설정하여 이를 확인해보고자 합니다:
\begin{equation}\min_w R_S[w]:=||Xw-y||^2_2.\label{eq4}\end{equation}
위의 문제에서 $X$는 $d$ dimensional feature들이 $n$개 sample에 대해 있는 $n \times d$ matrix이며 $y$는 $\{-1,1\}$를 label set으로 갖는 $n$ dimensional vector입니다. 우리는 이제 가장 적합한 linear classifier $w$를 찾기만 하면 되는 것이죠.
이전 글에서 Non-adaptive methods는 식 \ref{eq4}에 대해 minimum $l_2$ norm 을 갖는 해 $$w^{SGD}=X^T(XX^T)^{-1}y$$로 동일하게 수렴을 하는 반면, adaptive methods는 특별한 경우에 한하여 분석한 것이긴 합니다만 lemma 1에서 얘기한 조건이 맞는 경우, 앞서 소개한 모든 adaptive methods는 언제나 $w\propto sign(X^Ty)$인 해로 수렴한다는 것을 보여줍니다.
이번 글에서는 이 lemma에 대한 증명을 시작으로 "Adaptivity can overfit"에 대한 내용을 다뤄보도록 하겠습니다.
Suppose $X^Ty$ has no components equal to $0$ and there exists a scalar $c$ such that $X sign(X^Ty)=cy$. Then, when initialized at $w_0=0$, AdaGrad, Adam, and RMSProp all converge to the unique solution $w\propto sign(X^Ty)$.
증명이 생각보다 매우 쉽습니다. 먼저 이 lemma를 증명하기 위해 어떤 전략을 사용할 것인지 설명드리겠습니다. 위에 lemma에서 설정한 $Xsign(X^Ty)=cy$인 scalar 값 $c$가 존재한다는 조건이 성립한다는 것을 전제로 다음식에 대해 귀납법을 통해 증명을 할 것입니다:
$$w_k = \lambda_k sign (X^Ty).$$
먼저 이 식이 $k=0$일 때, $w_0=0$으로 initial 값을 주면 $\lambda_k=0$로 성립을 합니다. 귀납법의 첫째 단계는 통과했으니 다음 단계로 $k\leq t$일 때 assertion이 holds한다면 어떻게 되는지 확인해보시죠:
\begin{align*} \nabla R_S(w_k+\gamma_k(w_k-w_{k-1})) &= X^T(X(w_k+\gamma_k(w_k-w_{k-1}))-y) \\ &= X^T\{(\lambda_k+\gamma_k(\lambda_k-\lambda_{k-1}))Xsign(X^Ty)-y\} \\
&= \{\lambda_k +\gamma_k(\lambda_k-\lambda_{k-1}))c-1\}X^Ty \\
&= \mu_k X^Ty. \end{align*}
첫번째 등호에서 두번째 등호로 넘어가는 것은 $w_k = \lambda_k sign (X^Ty)$를 대입한 것이므로 간단합니다. 세번째 등호로 넘어가는 것 역시 가정에 의해 $Xsign(X^Ty)=cy$를 만족하는 $c$가 있으므로 이를 대입합니다. 남아 있는 것은 상수들뿐이기 때문에 여기서 $\mu_k$는 마지막 식에 의해 자연스럽게 정의됩니다.
따라서 $g_k=\nabla R_S(w_k+\gamma_k(w_k-w_{k-1}))$로 놓으면,
\begin{align*} H_k &= diag\left( \left\{ \sum_{s=1}^k \eta_s g_s \circ g_s \right\}^{1/2} \right)= diag\left( \left\{ \sum_{s=1}^k \eta_s \mu_s^2 \right\}^{1/2} |X^Ty| \right) \\&= \nu_k diag(|X^Ty|) \end{align*}
여기서 $|\cdot|$는 component-wise 절대값입니다 그리고 역시 마지막 식으로 $\nu_k$를 정의됩니다.
따라서 앞서 정의했던 $w$ update 식에 의해
\begin{align*} w_{k+1}&=w_k-\alpha_kH_k^{-1}\tilde{\nabla}f(w_k+\gamma_k(w_k-w_{k-1}))+ \beta_kH_k^{-1}H_{k-1}(w_k-w_{k-1}) \\
&= \left\{ \lambda_k - \frac{\alpha_k \mu_k}{\nu_k} + \frac{\beta_k\nu_{k-1}}{\nu_k}(\lambda_k-\lambda_{k-1}\right\} sign(X^Ty) \end{align*}
가 되고 $\tilde{\nabla}f$는 위에서 구한 $\nabla R_S$를 대입한 것입니다. 이로써 마지막 줄이 결국 $k+1$에 대해서도 식이 성립하는 것을 보였으므로 증명이 끝납니다.
이 lemma에 의해 $X sign(X^Ty)=cy$를 만족하는 상수 $c$가 존재하고 $Xw = y$의 문제에 대해 $sign(X^Ty)$에 비례하는 해 $w$가 있을 경우, adaptive methods는 언제나 그 해로 수렴한다는 것입니다. 이렇게 간단한 해가 새로운 데이터에 대해 일반화가 잘 된다면 그게 더 신기한 일이겠죠. 실제로 이런 해들이 일반화에 관점에서 상당히 좋지 않다는 것을 다음 단락에서 보여줍니다.
Adaptivity can overfit
이제 생각보다 범용적인 상황의 간단한 예제에서 위에 lemma 1의 조건이 성립하는 경우 실제로 AdaGrad가 좋은 해(일반화가 잘 되는)를 찾지 못하는 것을 보여드리겠습니다.
이 예제는 간단하게 설명을 하기 위해 infinite dimensions를 사용합니다만 $n$개의 sample들에 대해 parameter dimension이 $6n$개를 만족하기만 하면 됩니다. 보통 실제 상황에서는 parameter의 수가 보통 $25n$이나 그 이상임을 생각하면, 이 예제의 설정이 이상한 것이 아닙니다.
Sample $i=1,\cdots,n$개에 대해 label $y_i$가 $p>1/2$인 확률 $p$로 $y_i=1$, $1-p$의 확률로 $y_i=-1$이고 $x$가 다음과 같은 infinite dimensional vector라고 해보겠습니다:
$$x_{ij} =\left\{\begin{array}{lll} y_i\hspace{10pt}j = 1 \\
1 \hspace{10pt}j = 2,3 \\
1 \hspace{10pt}j = 4+5(i-1),\cdots,4+5(i-1)+2(1-y_i) \\
0 \hspace{10pt} otherwise \end{array}\right.$$
$x$의 구조를 잘 살펴보시면 $x_i$의 feature라고 할만한 것은 class label을 갖는 첫번째 element뿐입니다. 다음 두 element들은 항상 1이고 그 이후로는 $x_i$에 대해 unique하기 때문에 sample의 label을 구별하는데 전혀 도움이 되지 않습니다. 예를 들어 sample $x_i$의 class가 1이면 한 slot만 1이고 class가 $-1$이면 5개 slot에 1이 들어가 마치 $x_i$에 대한 code와 같이 값이 들어가 있는 형태입니다.
즉, 첫번째 element만을 잘 뽑아내면 완벽한 classification이 가능합니다. 다만 이런 선행 정보가 전혀 없다면 adaptive methods가 $arg\min_w||Xw-y||^2$ 문제를 풀 때 이러한 classifier를 전혀 찾지 못한다는 것을 확인해보겠습니다.
먼저 이 문제가 lemma에서 얘기한 조건들을 만족한다는 것부터 보여야겠죠. $b=\sum_{i=1}^ny_i$이고 편의상 $b>0$라 할 때 (상당히 높은 확률로 large enough $n$에 대해 그럼직하죠), $u=X^Ty$라고 정의하면 $u$의 구조는 아래와 같습니다:
따라서 일단 $u$의 elements 중 값이 0인 원소가 존재하지 않아 lemma의 첫번째 조건을 만족하며, 두번째 조건 역시 *$<sign(u),x_i>=y_i+2+y_i(3-2y_i)=4y_i$이므로 scalar $c=4$가 존재합니다. 그러므로 lemma에 의해 AdaGrad의 해는 $w^{ada}\propto sign(u)$가 됩니다. * paper에는 $<sign(u),x_i>$가 아닌 $<u,x_i>$로 되어있는데 잘못으로 보입니다.
따라서 임의의 양의 상수 $\tau$에 대해 $w^{ada}$는 언제나 0 혹은 $\pm \tau$를 원소로 갖습니다. 이제 새로운 데이터 $x^{test}$에 대해 이렇게 구한 해가 어떤 식으로 반응하는지 생각해봅시다. $x^{test}$와 $w^{ada}$ 둘 다 0이 아닌 유일한 features는 첫 3개 dimensions뿐입니다. 나머지는 서로 unique한 위치에 값을 갖기 때문에 곱하면 0일뿐이죠. 따라서 $w^{ada}$는 다음과 같이 처음 보는 데이터에 대해 항상 positive class로 분류하게 됩니다!!:
$$<w^{ada},x^{test}>=\tau(y^{test}+2)>0.$$
그럼 minimum norm solution은 어떤지 확인해볼까요? $\cal{P}$와 $\cal{N}$이 각각 positive 그리고 negative 예제들의 집합을 나타낼 때, $n_+=|\cal{P}|$이고 $n_-=|\cal{N}|$라 합시다. 이 때, symmetry에 의해 우리는 minimum norm solution이 아래와 같은 음이 아닌 상수 $\alpha_+$와 $\alpha_-$에 대해 $w^{SGD}=\sum_{i\in\cal{P}} \alpha_+ x_i -\sum_{j\in\cal{N}} \alpha_{-}x_j$ 와 같은 형태를 갖는 다는 것을 알 수 있습니다:
이 수식과 상수들을 계산하는 법은 논문의 Appendix를 참고하시면 됩니다 (논문의 주안점이 아니기 때문에 굳이 설명하지 않겠습니다).
우리가 원하는 것은 이런 해가 새로운 데이터에 대해 어떻게 반응하냐는 것이었죠? 위와 마찬가지로 $x^{test}$가 들어왔을 때, $x^{test}$와 $w^{SGD}$ 둘 다 0이 아닌 유일한 features는 첫 3개 dimensions뿐입니다:
$$<w^{SGD},x^{test}>=y^{test}(n_+\alpha_++n_-\alpha_-) + 2(n_+\alpha_+-n_-\alpha_-).$$
앞서 계산한 상수 $\alpha_+$와 $\alpha_-$에 의해 $n_+>N_-/3$일 때는 SGD는 언제나 제대로 분류를 한다는 것을 알 수 있습니다.
물론 이 예제가 약간 극단적이라 생각할 수 있습니다만, 생각보다 우리가 마주하는 기계학습 예제들의 상황과 상당히 비슷한 특징들을 잘 보여주고 있습니다. 보통 몇몇 feature들만을 사용하면 상당히 좋은 predictor를 만들 수 있지만 이를 처음부터 딱 알기는 쉽지 않습니다 (마치 첫번째 원소만 사용하면 되지만 선행지식이 없어 그렇게 classifier를 구성하지 못한 것과 같이). 게다가 많은 경우, 데이터의 feature들이 매우 sparse합니다. Training data가 finite할 경우 이런 feature들이 training data를 구별하는 것에는 매우 좋아 보일 수 있으나 사실 그 값들이 artifact로 인한 noise일 수도 있고 이에 맞춰 classifier를 만들 경우 over-fitting 현상이 생길 우려도 있기에 좋다고 할 수는 없습니다.
이 논문에서는 앞서 설명한 이론적 분석에 더불어서 실험적으로도 adaptive methods들로 구한 해들이 generalization performance가 non-adaptive methods로 구한 해에 비해 좋지 않다는 것을 확인해주는데요. 이 부분은 결과를 보시면 되기 때문에 이 글에서는 굳이 더 설명하지 않도록 하겠습니다.
내 멋대로 정리 및 결론
다시 한 번 이 논문에서 저자들이 주장하는 내용을 요약해보자면 아래와 같습니다:
같은 수의 hyperparameter tuning을 할 때, SGD와 SGD+momentum이 여타 adaptive methods들보다 모든 모델과 task들에 대해 dev/test set에서 우월한 결과를 보여줌.
Adaptive methods들이 초기 학습 속도는 빠른 모습을 종종 보이긴 하지만 dev/test set에서 성능이 증가하는 것 역시 더 빠르게 더뎌지는 모습을 보임.
Adaptive methods들이 주장하는 장점인 "less tuning needed"와는 다르게 모든 methods들에 동일한 정도의 tuning이 필요했음.
다만 GAN이나 Reinforcement Learning 분야의 경우 Adam이나 RMSProp과 같은 adaptive methods가 매우 잘 들어맞는 경우가 있고 이런 경우에 대해서는 저자들도 정확히 이유를 알지 못하겠다고 결론을 내립니다. 다음과 같이 추측을 할뿐인데요 이 부분은 뉘앙스가 애매할 수 있으므로 원문을 그대로 가져와 보겠습니다.
In our conversations with other researchers, we have surmised that adaptive gradient methods are particularly popular for training GANs [5, 18] and Q-learning with function approximation [9, 13]. Both of these applications stand out because they are not solving optimization problems. It is possible that the dynamics of Adam are accidentally well matched to these sorts of optimization-free iterative search procedures.
이 부분들은 사실 좀 애매한데요 GAN은 아마도 saddle 문제이기 때문에 이렇게 얘기하는 것 같습니다. Q-learning의 경우에도 전원석님이 답변해주신 내용을 여기에 정리해보자면 다음과 같습니다.
Deep reinforcement learning에서 RMSProp을 쓰는 주된 이유 중에 하나는 현재의 gradient update로 policy가 크게 바뀌면 앞으로 들어올 data가 망가지고 다음 policy에 악영향을 미쳐 전체 학습을 망치게 되는데 이를 방지하기 위함으로 알고 있습니다. 논문에서 최적화 문제가 아니라고 함은 아마 주어진 데이터셋이 있고 loss minimization을 하는 상황이 아니라는 걸 의미하지 않나 생각합니다.
결국 제가 보기에는 이 논문의 캐치 프레이즈였던 "SGD를 써라!"는 역시 case by case인 것으로 생각됩니다. 여전히 우리가 예측하지 못하는 혹은 보지 못하는 dark matter가 DL에는 남아있고 (물론 저자들은 자신들이 설정한 예제가 꽤나 broad한 설정이라고 주장하고 있지만) 항상 장님 코끼리 만지고 있는 것과 같이 매우 일부분의 degenerate한 경우일 수 있기에 이 논문만을 믿고 SGD만 사용하기보다는 역시 여러 시도를 해보는 수 밖에 없다는 어찌보면 싱거운? 결론에 이릅니다.
DARK MATTER IN DEEP LEARNING
하지만 여전히 이렇게 이론적으로 Deep learning의 요소들을 파헤쳐 설명하고자 하는 theoretical machine learning 분야는 참 매력적인 분야입니다. 왜 DL이 잘 working하는가를 설명하면서 새로운 디자인 방식과 같은 내용을 제안하는 연구들을 보면 매우 멋지죠. 제 꿈 중 하나가 이렇게 DL의 working principle을 이론적으로 파헤치는 것인데요 아직은 내공이 매우 부족하여 꿈으로만 그치고 있습니다. 느리더라도 거북이 같이 공부를 하다보면 언젠가는 닿을 수 있길 기대하고 있습니다.
: Baby steps to your neural network's first memories.
* This is the Korean translation of the original post by @iamtrask under his permission. You can find the English version at his blog: here. 저자의 허락을 득하고 번역하여 옮깁니다.
안녕하세요 한동안 뜸했습니다. 일주일 간의 파키스탄 출장이 끝나서 어제 돌아왔네요. 이 논문은 출장 중 페이스북을 보다가 최근에 흥미로운 논문 한 편이 공유되었길래 저장해뒀던 것인데요 돌아오는 비행기 안에서 시간을 보낼거리를 찾다가 상당히 재미있게 읽어 글로 정리를 해봅니다.
논문 내용을 마치 광고 글처럼 요약해보자면,
"Gradient descent (GD)나 Stochastic gradient descent (SGD)를 이용하여 찾은 solution이 다른 adaptive methods (e.g. AdaGrad, RMSprop, and Adam)으로 찾은 solution보다 훨씬 generalization 측면에서 뛰어나다."
요즘 랜섬웨어가 유행한다고 하네요 아래의 처치로 일차적으로 보안 취약점 하나를 막을 수 있으니 따라해보시길 권합니다.
1. 랜섬웨어 방지 대국민 행동
1) PC를 켜기 전 네트워크 단절
- 랜선 뽑기
- 와이파이 끄기
2) 감염 경로 차단
- 방화벽 설정 변경
3) 인터넷 재연결 후 보안 업데이트
- 윈도우 보안 패치 실행
- 백신 프로그램 업데이트
2. 파일 공유 기능 해제 - 방화벽 설정
Window 방화벽에서 SMB에 사용되는 포트 차단
1) 제어판 -> 시스템 및 보안
2) Windows 방화벽 -> 고급 설정
3) 인바운드 규칙 -> 새규칙 -> 포트 -> 다음
4) TCP -> 특정 로컬 포트 -> 139,445 -> 다음
5) 연결 차단 -> 다음
6) 도메인, 개인, 공용 체크 확인 -> 다음
7) 이름 설정 -> 마침
매주 일요일 두 명이 각각 40분 동안 발표하고 질문을 받으며 진행하게 되었는데요 그 첫 머리를 제가 GAN으로 시작하는 영광을 얻었습니다. 이런 촬영이 처음이라 맨 뒤에 GAN variants를 소개하다가 40분을 초과하여 살짝 끊겼지만 그래도 주요한 내용은 모두 커버해서 다행입니다. 다음부터는 타이머를 켜두려구요.
안녕하세요 오늘은 GAN 시리즈 대신 GAN 이전에 generative model계를 주름잡고 있었던 Variational Auto-Encoder a.k.a. VAE에 대해 살펴보겠습니다. 그동안 논문들을 보다보면 GAN과 VAE를 비교하며 어떤 차이점이 있는지에 대해 여러 차례 언급이 되었기에 제대로 보지는 않았는데도 익숙할 지경입니다.
원래 뭐든 이름을 제대로 알면 다 아는거라고 하죠? :) 그럼 이름에 왜 "Variational"이 들어가고 "Auto-Encoder"는 어떻게 쓰이는지 확인해보겠습니다.
지난 글에 이어 BEGAN 내용을 쭉 살펴보고 마무리해보겠습니다. 마지막 부분에 얘기했었지만 GAN에서는 generator와 discriminator 사이의 파워 게임에서 균형을 맞춰주는 것이 매우 중요합니다. 이 균형이 잘 안 맞으면 discriminator가 generator를 쉽게 이기는 경우가 많은데 BEGAN에서는 이 부분도 equilibrium measure technique이라는 개념을 도입해서 일부분 해결을 해줍니다. 심지어 한 쪽이 좀 더 학습이 잘 된 경우에도 모델이 안정적으로 학습되게 해준다는 것을 실험 결과로도 보여줍니다.
Hot한 논문은 빨리 리뷰해야 제맛이죠. 3월 31일날 arXiv에 올라온 따끈따끈한 논문인데 커뮤니티 사이트에 올라오는 글 덕에 편하게 살펴보다가 깜짝 놀랐습니다. 구글은 역시 구글인가 봅니다. 결과가 아주 어마무시하네요. 본문 중에
" We focus on the image generation task, setting a new milestone in visual quality, even at higher resolutions."
라는 말이 나오는데 과연 milestone이라 자신할만한 결과입니다...이름도 정말 멋지게 잘 지었습니다. BEGAN이라니.
BEGAN으로 생성된 이미지들 (구글이 정말 미쳤습니다..)
정말 이 정도면 data augmentation을 해도 되지 않나 하는 생각이 듭니다. 이 결과만 해도 128 X 128 이미지 사이즈로 생성된 것인데 사실 확대해서 보아도 어색함을 느끼기가 어려울 정도입니다. 처음엔 실제 데이터 이미지를 소개하는 것을 잘못 이해했나 하고 캡션을 다시 봤을 정도입니다.
BEGAN의 contribution
저자들이 얘기하는 BEGAN의 contribution은 다음과 같습니다 (하나하나 따로만 봐도 빠질 것이 없네요):
단순하지만강력한 구조와 빠르고 안정적인 학습과 수렴이 가능한 GAN
Discriminator와 generator 사이의 균형을 조정해주는 equilibrium contept
이미지의 다양성과 질(quality) 사이의 trade-off를 조정하는 것이 가능한 새로운 방법
"수렴"의 approximate measure
BEGAN은 기본적으로 앞서 나온 EBGAN과 WGAN에서 얻은 아이디어와 지금까지 개발된 다른 테크닉을 잘 사용해서 (물론 새로운 아이디어도 많이 있으나) 이렇게 좋은 결과를 만들어냅니다. 여기에 더해 (이미 알려진 것을 잘 사용하는 것도 정말 능력입니다만 이렇게까지 좋게 만들 수 있을 지는 상상도 못했네요.)
일단 BEGAN은 EBGAN과 상당히 닮은 뼈대를 가지고 있습니다. EBGAN이 discriminator에 auto-encoder를 사용하였던 것과 마찬가지로 BEGAN도 auto-encoder를 사용합니다. 다만 한 가지 중요한 다른 점은 일반적인 GAN이 data distribution을 맞추기 위해 학습하는 것에 반해 BEGAN은 auto-encoder loss distribution을 맞추려 한다는 것입니다. 이 때 Wasserstein distance를 사용한다는 점도 per-pixel Euclidean distance를 사용하는 EBGAN과는 다른 점입니다.
저번 글에 이어 LSGAN의 장점과 f-divergence와의 관계 등을 수식과 함께 좀 더 구체적으로 살펴보겠습니다.
LSGAN의 장점
LSGAN의 장점은 크게 두 가지로 나눌 수 있습니다. 지난 글에서도 언급했었지만 기존 GAN은 generator가 만든 sample이 실제 data distribution과 거리가 멀지라도, sigmoid cross entropy loss function 입장에서는 일단 discriminator를 속이기만 하면 문제가 없기 때문에 별다른 피드백을 주기 어렵습니다 (아래 그림).
Sigmoid decision boundary
하지만 LSGAN은 least square loss function을 사용하여 sample이 decision boundary로부터 멀리 떨어져 있는 경우 거리에 따라 패널티를 주기 때문에 generator가 좀 더 decision boundary에 가까운 (hopefully or approximately data distribution에 가까운) sample을 만들도록 할 수 있습니다.
LSGAN의 두번째 장점도 이 loss function과 관련이 있습니다. 아래 그림에서 보실 수 있듯이 $x$ 값에 따라 saturate 될 수 있는 sigmoid cross entropy loss function과는 달리 least square loss function이 오직 한 점에서만 최소값을 갖기 때문에 LSGAN이 좀 더 안정적인 학습이 가능하다고 설명하는군요.
(a) The sigmoid cross entropy loss (b) The least square loss
점점 읽은 논문은 쌓여가고 포스팅은 속도가 느려 따라가지 못하는 상황이 많이 발생합니다. 하루에 읽고 쓰고 처리할 수 있는 정보의 양이 한정적이란 것이 정말 아쉽습니다. 세상에 보고 읽고 공부해서 해봐야할 것들이 정말 많은데 좀 더 효율적인 방법 없을까..하는 생각이 들곤합니다. 머리에 GPU를 달 수도 없고...orz... 이럴땐 처리 속도가 빠른 천재들이 부럽습니다.
그런 의미에서!? 아직 InfoGAN에서 하고픈 얘기가 좀 남았지만 최근 읽은 논문 하나를 더 소개해보고자 합니다. (일단 저질르면 언젠가는 다 마무리하겠지..-_-...)
사실 순서대로 따지면 f-GAN을 한 번 소개하고 WGAN과 그 직전에 WGAN의 모태가 된 논문도 정리하고 뭐 할 것이 많지만....
어느 세월에 다 쓰나싶어 거두절미하고 이해하기 편하고 쓰기 편한 LSGAN부터 올리기로 했습니다! 이름부터 뭔가 편합니다. Least Square는 regression이나 optimization을 공부하면 가장 처음에 나오는 내용이죠. 매우 익숙한데 얘를 어떻게 이용하는지 한 번 살펴보겠습니다.
지난 글에 이어 오늘은 InfoGAN의 이론적인 부분을 중점적으로 살펴보도록 하겠습니다. 저번에 얘기했던 내용을 짧게 정리해보면 다음과 같습니다
기존의 GAN과는 달리 InfoGAN은 생성 모델에 들어갈 Input에 latent code $c$를 추가하여 학습합니다. 이 때, 무의미한(trivial) code가 학습되는 것을 막기 위해 생성 모델의 분포 $G(z,c)$와 상호 정보량(Mutual Information, MI)이 높도록 제약을 부여합니다. 즉, $I(c;G(z,c)$가 높게 유지시킵니다.
"In other words, the information in the latent code $c$ should not be lost in the generation process."
즉, $c$가 생성 모델을 지나는 동안 변형되지 않는 뭔가 중요한 정보를 담도록 학습하길 기대하는 것입니다.
결과적으로 InfoGAN은 아래와 같은 information-regulaized minimax 문제를 풉니다: $$\min_G \max_D V_I(D,G) =V(D,G)-\lambda I(c;G(z,c)).$$
오늘은 InfoGAN이라는 논문을 소개하고자 합니다. 정보 이론(information-theoretic)에서 아이디어를 가져와 GAN에 붙여 확장한 것인데, 어려워 보이는 수식어가 붙는 것에 비해 아이디어가 상당히 간단하고 매우 흥미로운 결과를 보여줍니다. 더불어 original GAN을 다른 관점으로 분석하는 길을 열어주기 때문에 GAN을 더 깊히 이해하는데 도움이 될 것이라 생각합니다.
기본적인 아이디어는 다음과 같습니다. 기존의 GAN은 생성 모델의 input이 $z$ 하나인 것에 비해 InfoGAN은 ($z,c$)로 input에 code라는 latent variable $c$가 추가됩니다. 그리고 GAN objective에 애드온(add-on)을 하나 붙여서 생성 모델이 학습을 할 때, latent 공간($z$-space)에서 추가로 넣어준 코드 $c$와 생성된 샘플(generated sample) 사이의 Mutual Information (MI)가 높아지도록 도와줍니다.
* Korean version of this content is available at HERE.
Today, I am going to review an educational tutorial which was delivered in NIPS 2016 by Prof. Andrew Ng. As far as I know, there is no official video clip available but you can download the lecture slides by searching in internet.
You can see the video with almost identical contents (even the title is exactly the same) in the following link:
* I really recommend you guys to listen to his full lecture. However, watching video takes too much time to get an overview quickly. Here, I summarized what he tried to deliver in his talk. I hope this helps. ** Note that I skipped a few slides or mixed the order to make it easier for me to explain.
How do you get deep learning to work in your business, product, or scientific study? The rise of highly scalable deep learning techniques is changing how you can best approach AI problems. This includes how you define your train/dev/test split, how you organize your data, how you should think through your search among promising model architectures, and even how you might develop new AI-enabled products. In this tutorial, you’ll learn about the emerging best practices in this nascent area. You’ll come away able to better organize your and your team’s work when developing deep learning applications.
Trend #1
Q) Why is Deep Learning working so well NOW?
A) Scale drives DL progress
The red line, which stands for the traditional learning algorithms such as SVM and logistic regression, shows a performance plateau in the big data regime (right-hand side of the x-axis). They did not know what to do with all the data we collected.
For the last ten years, due to the rise of internet, mobile and IOT (internet of things), we could march along the X-axis. Andrew commented that this is the number one reason why the DL algorithm works so well.
So... the implication of this :
To hit the top margin, you need a huge amount of data and a large NN model.
Trend #2
According to Ng, the second major trend is end-to-end learning.
Until recently, a lot of machine learning used real or integer numbers as an output, e.g. 0 or 1 as a class score . In contrast to those, end-to-end learning can give much more complex output than numbers, e.g. image captioning.
It is called "end-to-end" because the input and output of the system are directly linked by a neural network unlike traditional models which have several intermediate steps. This works well in many cases that are not effective while using traditional models. For example, end-to-end learning shows a better performance in speech recognition tasks:
While presenting this slide, he introduced the following anecdote:
"This end-to-end story really upset many people. I used to get around and say that I believe "phonemes" are the fantasy of the linguists and machines can do well without them. One day at the meeting in Stanford a linguist yelled at me in public for saying that. Well...we turned out to be right."
This story seems to say that end-to-end learning is a magic key for any application but rather he warned the audience that they should be careful while applying the model to their problems.
Despite all the excitements about end-to-end learning, he does not think that this end-to-end learning is the solution for every application.
It works well in "some" cases but it does not in many others as well. For example, given the safety-critical requirement of autonomous driving and thus the need for extremely high levels of accuracy, a pure end-to-end approach is still challenging to get to work for autonomous driving.
In addition to this, he also commented that even though DL can almost always train a mapping from X to Y with a reasonable amount of data and you may publish a paper about it, it does not mean that using DL is actually a good idea, e.g. medical diagnosis or imaging.
End-to-End works only when you have enough (x,y) data to learn function of needed level of complexity.
I totally agree with the above point that we should not naively rely on the learning capability of the neural network. We should exploit all the power and knowledge of hand-designed or carefully chosen features which we already have.
In the same context, however, I have a slightly different point of view in "phonemes". I think that this can and should be also used as an additional feature in parallel which can reduce the labor of the neural network.
Machine Learning Strategy
Now let's move on to the next phase of his lecture. Here, he tries to give a glimpse of answer or guideline to the following issues:
Often you will have a lot of ideas for how to improve an AI system, what will you do?
Good strategy will help avoid months of wasted effort. Then, what is it?
I think this part is a gist of his lecture. I really liked his practical tips all of which can be actually applied in my situations right away.
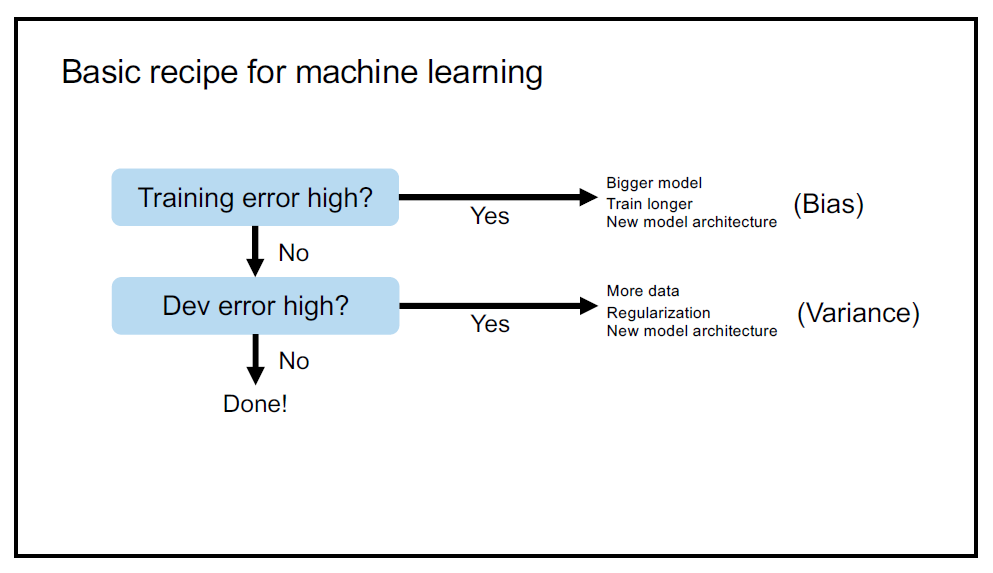
One of those tips he proposed is a kind of "standard workflow" which guides you while training the model:
When the training error is high, this implies that the bias between the output of your model and the real data is too big. To mitigate this issue, you need to
train longer,
use bigger model
or adopt a new one.
Next, you should check whether your dev error is high or not. If it is, you need
more data,
regularization
oruse a new model architecture.
* Yes I know, this seems too obvious. Still, I want to mention that everything seems simple once it is organized under an unified system. Constructing an implicit know-how to an explicit framework is not an easy task. Here, you should be careful with the implication of the keywords, bias and variance. In his talk, bias and variance have slightly different meanings than textbook definitions (so we do not try to trade off between both entities) although they share a similar concept. In the era before DL, people used to trade off between the bias and variance by playing with regularization and this coupling was not able to overcome because they were tied too strongly. Nowadays, however, the coupling between these two seems like to become weaker than before because you can deal with both separatelyby using simple strategies, i.e. use bigger model (bias) and gather more data (variance).
This also implicitly shows the reason why DL seems to be more applicable to various problems than the traditional learning models. By using DL, there are at least two ways to solve the problems which we are stuck in real life situations as mentioned above.
Use Human Level Error as a Reference
To know whether your error is high or low, you need a reference. Andrew suggests to use a human level error as an optimal error, or Bayes error . He strongly recommended to find the number before going deep in research because this is the very critical component to guide your next step.
Let's say our goal is to build a human level speech system using DL. What we usually do with our data set is to split them with three sets; train, dev(val) and test. Then, the gaps between these errors may occur as below:
You can see the gaps between the errors are named as bias and variance. If you take time and think a while, you will find that it is quite intuitive why he named the gap between human level error and training set error as bias and the other as variance.
If you find that your model has a high bias and a low variance, try to find a new model architecture or simply increase the capacity of the model. On the other hand, if you have a low bias but a high variance, you would be better to try gathering more data as an easy remedy. To see this more clearly, let's say you have the following results:
Train error : 8%
Dev error : 10%
If I were to tell you that human level error for such a task is of the order of 1%, you will immediately notice that this is the bias issue. On the other hand, if I told you that human level error is around 7.5%, this would be now more like a variance problem. Then you would be better to focus your efforts on the methods such as data synthesis or gathering the data more similar to the test. As you can see, just because you use a human level performance as a baseline, you can always have guidelines where to focus on among several options you may have.
Note that he did not say it is "easy" to train a big model or to gather a huge amount of data. What he tries to deliver here is that at least you have an "easy option to try" even though you are not an expert in this area. You know... building a new model architecture which actually works is not a trivial task even for the experts. Still, there remains some unavoidable issues you need to overcome.
Data Crisis
To deal with a finite amount of data to efficiently train the model, you need to carefully manipulate the data set or find a way to get more data (data synthesis). Here, I will focus on the former which brings more intuitions for practitioners.
Say you want to build a speech recognition system for a new in-car rearview mirror product. You have 50,000 hours of general speech data and 10 hours of in-car data. How would you split your data?
This is a BAD way to do it:
Having a mismatched dev and test distributions is not a good idea. You may spend months optimizing for dev set performance only to find it does not work well on the test set.
So the following is his suggestion to do better:
A few remarks
While the performance is worse than humans, there are many good ways to progress;
error analysis
estimate bias/variance
etc.
After surpassing the human performance or at least near the point, however, what you usually observe is that the progress becomes slow and almost gets stuck. There can be several reasons for that such as:
Label is made by human (so the limit lies here)
Maybe the human level error is close to the optimal error (Bayes error, theoretical limit)
What you can do here is to find a subset of data that still works worse than human and make the model do better.
Andrew ended the presentation with emphasizing two ways one can improve his/her skills in the field of deep learning;
practice, practice, practice and do the dirty work
(read a lot of papers and try to replicate the results).
which happen to be exactly a match with my headline of blog. I am glad that he and I share a similar point of view:
READ A LOT, THINK IN PICTURES, CODE IT, VISUALIZE MORE!
I hope you enjoyed my summary. Thank you for reading :)
 Korean
Korean English
English