 Korean
Korean English
English오늘은 클래식한 내용을 다뤄볼까 합니다. 기계 학습 분야에서 한 시대를 풍미하였고, 여전히 매우 다양한 현장에서 사용되고 있는 Support Vector Machine (SVM)에 대해 정리해보았습니다.
SVM은 이미 역사가 오래되기도 하였지만 매우 멋진!! 방법이기에 여러 학습 자료들이 있습니다. 그런데도 불구하고 제가 그 많은 자료에 하나를 더 추가하는 까닭은 이 영상만큼 간결하지만 핵심을 관통하는 자료를 본 적이 없기 때문입니다. 오직 스스로를 위해 이 강의의 Insight를 잊기 전에 정리하고자 글을 적어봅니다.
MIT OCW는 정말 은혜로운데요 이 글을 찾으신 분들 중 시간이 있는 분들은 제 정리 글을 보기 보다는 시간을 내어 꼭 영상을 직접 보시는 것을 추천합니다. 이렇게 넓고 깊은 시야를 지닌 교수님께 강의를 온라인으로나마 들을 수 있다는 것은 정말 축복입니다.
슬프지만 시간이 없으신 분들께서 (혹은 미래에 내용을 까먹은 내가...) 이 글만으로도 강의의 핵심을 맛볼 수 있도록 최대한 노력하여 정리해보겠습니다.
Support Vector Machine
SVM의 매력은 매우 아름답고 탄탄한 이론적인 배경을 바탕으로 정교하게 고안된 기계학습 알고리즘이라는 것에 있습니다. 여기에 알고리즘의 실제 적용이 여러 모로 쉽고 성능이 강력하며 따라서 실전적이라는 점이 그 매력을 더합니다.
SVM에서 풀고자 하는 문제는 다음과 같습니다.
"How do we divide the space with decision boundaries?"
예시와 함께 보면 좀 더 구체적으로 문제를 좁힐 수 있습니다:

- 우리가 $'+'$ 샘플과 $'-'$ 샘플을 구별하고 싶다면 어떤 식으로 나눠야 하는가?
- 만약 선을 그어 그 사이를 나눈다면 어떤 선이어야 할 것인가?
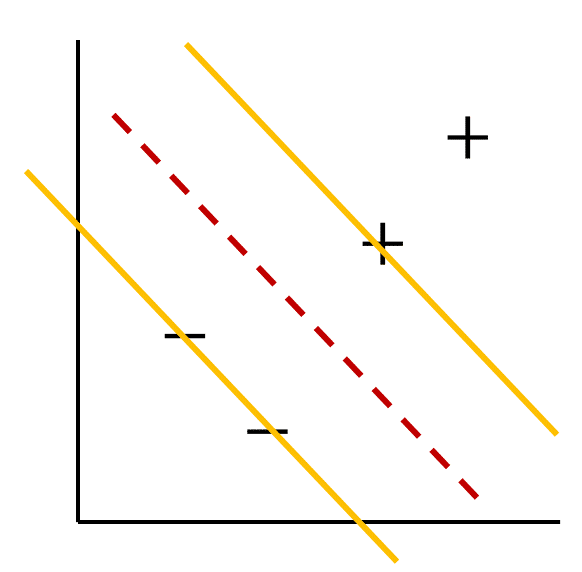
"widest street strategy"
흠... 매우 직관적으로 풀 수 있는 별 것 아닌 문제로 보입니다. 하지만 이 문제에 대한 답을 구체적이고 논리정연하게 이론으로 일반화하는 것은 언뜻 보기와는 달리 쉬운 작업이 아닙니다. SVM은 지금 던진 문제에 대한 답을 찾기 위해 풀어나간 과정입니다.
그래서 제가 오늘 정리하고자 하는 것은 SVM이기도 하지만 어떤 문제를 풀기 위해 체계적으로 아이디어를 개발하고 논리를 전개하는 과정 그 자체라고도 얘기할 수 있겠습니다. 그만큼 SVM은 매우 정교하게 고안된 알고리즘인데요 앞으로도 이런 관점에서 어떤 식으로 문제를 설정하고 어떻게 풀어나가는 지를 염두에 두면서 정리하고자 합니다. 이제 그 과정을 하나하나 따라가 보겠습니다.
Decision rule
그럼 먼저 "decision boundary를 정하기 위한 decision rule은 어떤 형태여야 할 것인가?"에 대해 생각해보겠습니다. 이를 위해 $\vec{w}$를 하나 그려볼텐데요 이 벡터는 우리가 그릴 street의 중심선에 대해 직교하는 벡터입니다. (일단 여기서 그 길이는 잠시 arbitrary로 제쳐두겠습니다.)

그리고 이제 모르는 샘플 $\vec{u}$ 하나가 있을 때 우리가 궁금한 것은 street를 기준으로 이 녀석이 오른쪽에 속할지 혹은 왼쪽에 속할지입니다. 자 여기서 우리가 해볼 수 있는 한 가지 방법은 $\vec{w}$와 $\vec{u}$를 내적한 후 그 값이 어떤 상수 $c$보다 큰 지를 확인하는 것입니다; $\vec{w}\cdot \vec{u} \geq c$. 혹은 일반성을 해치지 않는 범위에서 아래와 같이 얘기할 수도 있겠죠:
\begin{align} \vec{w}\cdot \vec{u}+b \geq 0 \qquad then \quad`+' \label{eq:dr}\end{align}
논리는 매우 간단합니다. 내적을 한다는 것은 위에 그림에서 $\vec{u}$를 $\vec{w}$에 projection 한다는 것이고, 그 길이가 길어서 어떤 경계를 넘으면 오른쪽, 짧으면 왼쪽에 속한다는 것을 생각해보면 쉽게 이해하실 수 있을 것입니다.
따라서 수식 \eqref{eq:dr}이 우리의 decision rule이 됩니다. 우리가 SVM을 이해하는데 필요할 가장 첫번째 도구이기도 합니다. 하지만 아직은 부족한 점이 많죠. 아직 우리는 저 수식에서 어떤 $\vec{w}$를 정해야하는지 어떤 $b$를 잡아야하는지 전혀 모릅니다. 다만 $\vec{w}$가 우리가 원하는 street의 중심선에 직교한다는 것 하나만 알 수 있을뿐이죠.
아쉽게도 그런 $\vec{w}$는 매우 다양하게 그릴 수 있기에 여기서 내릴 수 있는 판단은 아직 constraint가 부족하다는 것입니다. 그래서 앞으로 할 것은 우리가 $\vec{w}$와 $b$를 계산할 수 있도록 저 수식에 여러 제약 조건들을 추가해가는 작업이 되겠습니다.
Design and add additional constraints
자 그러면 이제 위의 식에서 조금 더 나아가서 $x_+$를 $`+'$ 샘플 $x_-$가 $`-'$ 샘플이라 할 때 다음과 같이 적어보겠습니다:
$$\vec{w} \cdot \vec{x}_+ + b \geq 1 \\ \vec{w} \cdot \vec{x}_- + b \leq -1$$
즉, `+' 샘플을 예를 들면 이 샘플에 대해서는 우리의 decision rule이 최소한 1보다는 큰 값을 주도록 해본 것입니다.
흠...문제가 좀 더 구체화된 것 같기는 합니다..그런데 여전히 문제가 쉬워지지는 않았네요...안 그래도 복잡한데 따로 노는 두 개의 식들을 다루는 것은 짜증나는 일이지요. 그래서 여기에 variable 하나를 고안해서 문제를 좀 바꿔보겠습니다. (이런 variable들을 추가하는 이유는 정말 단순히 그저 수학적으로 편리하기 위함입니다)
$$y_i=\begin{cases}\begin{align*}~1&\qquad for \quad `+' \\ -1&\qquad for \quad `-' \end{align*}\end{cases}$$
이제 이 $y_i$를 위에 수식에 각각 곱해보겠습니다.
$$y_i(\vec{w}\cdot\vec{x}_i+b) \geq 1$$
오! 이제 수식이 하나로 줄었습니다. 이걸 좀 정리하면 아래와 같고,
\begin{equation}y_i(\vec{w}\cdot\vec{x}_i+b) - 1 \geq 0 \label{eq:const}\end{equation}
여기서 등호가 성립할 때는 $\vec{x}_i$가 정확히 street의 양 쪽 노란 경계선에 정확히 걸쳐 있을 때라는 제약을 하나 더 추가해보겠습니다. 즉, 위에 그림에서 경계(노란선, gutters)에 걸칠 $`+'$ 샘플 하나와 $`-'$ 샘플 두 개에 대한 수식의 결과가 0이 되겠습니다.
\begin{equation}y_i(\vec{w}\cdot\vec{x}_i+b) - 1=0 \qquad for\quad \vec{x}_i \in노란선~(gutters)\label{eq:2}\end{equation}
이 쯤에서 다시 우리가 하고자 했던 목적을 재차 상기해보겠습니다. 우리가 하고 싶은 것은 어떤 선을 잡되 이로 인해 생기는 $`+'$ 샘플과 $`-'$ 샘플 사이의 거리를 가능한 최대로 넓게 하고 싶습니다. 그러면 일단 '거리'라는 것을 어떻게 표현할 수 있을지 고민해봐야 합니다.

$$WIDTH = (x_+-x_-)\cdot\frac{\vec{w}}{||\vec{w}||}$$
오! 그런데 \eqref{eq:2}번 수식 덕분에 위에 WIDTH의 분자를 계산하면,
\begin{align}WIDTH = \frac{2}{||\vec{w}||}\label{eq:3}\end{align}
가 된다는 것을 알 수 있습니다. 이 수식 \eqref{eq:3}이 SVM을 이해할 때 필요한 세번째 도구입니다.
Optimization techniques
식 \eqref{eq:3}이 있기에 우리는 WIDTH를 최대화하고 싶다는 목적을 다음과 같이 수식화하여 적을 수 있게됩니다:
$$\max \frac{1}{||\vec{w}||} \leftrightarrow \min ||\vec{w}|| \leftrightarrow \min \frac{1}{2}||\vec{w}||^2$$
(이렇게 표현 하는 것 역시도 오로지 최종 목적을 위해서 그리고 수학적 계산의 용이함을 위함입니다.)
단, 이 문제를 풀 때 $\vec{w}$가 수식 \eqref{eq:2}이라는 제약 조건을 만족시켜야 한다는 점을 잊으면 안 됩니다. 이런 등식 제약 조건이 있는 최적화 문제는 다양하게 연구되어 왔는데, 많이들 알고 계시는 라그랑주 승수법(Lagrange Multiplier Method)를 적용하면 제약 조건을 신경쓰지 않고 풀 수 있도록 문제를 바꿀 수 있습니다:
\begin{equation} \cal{L}(w,b,\alpha) = \frac{1}{2}||\vec{w}||^2-\sum_{i=1}^N\alpha_i[y_i(\vec{w}\cdot\vec{x}_i+b)-1]\\ minimize\quad w.r.t.\quad \vec{w}~and~b \qquad maximize\quad w.r.t.\quad \alpha_i \geq 0 \quad \forall i\label{eq:4} \end{equation}
여기서 $\alpha$는 Lagrange multiplier입니다.
(* 나중에 얘기하게 되겠지만 $\alpha$들 중 경계에 걸친 샘플 $\vec{x}_i$(or support vector)에 대한 $\alpha_i$ 외에는 모두 값이 $0$이 됩니다. 그리고 모든 샘플들에 대해 얘기하려 하면 등식이 아닌 부등식 \eqref{eq:const}를 제약 조건으로 사용해야 하는데요 이 때는 KKT 조건이란 것을 설명해야 합니다. 엄밀히 말하면, 위 식 \eqref{eq:4}에서 $\alpha_i\geq0$라는 것과 $\alpha$에 대해 maximize 문제가 나온 이유 등이 이로부터 비롯합니다. 다만 이런 내용들을 지금 얘기하기에는 지금까지 전개해온 큰 흐름을 놓칠 우려가 있기에 당장은 이 녀석들이 해주는 역할이 제약 조건이 있는 최적화 문제를 제약 조건이 없는 문제로 바꾸어 주는 것이라는 점만 알고 넘어가겠습니다.)
이제 거의 다 왔습니다. 우리가 관심있는 각각의 변수에 대해 미분을 해주면 다음 식들을 얻을 수 있습니다.
\begin{align} \nabla_\vec{w}\cal{L} = \vec{w} - \sum_i\alpha_i y_i\vec{x}_i = 0 \label{eq:w}
\\ \nabla_b\cal{L} = -\sum_i\alpha_i y_i = 0 \label{eq:b}\end{align}
흠 매우 흥미로운 결론입니다. Now the math begins to sing! 여기서 첫번째 식을 정리해보면 $\vec{w} = \sum_i\alpha_iy_i\vec{x}_i$이므로 우리가 관심있는 decision vector $\vec{w}$가 "some" 샘플들의 선형 합으로 나타낼 수 있다는 점을 알 수 있습니다. $\vec{w}$는 꼭 이런 형태야 할 필요는 없었는데 말이죠. 차분히 문제를 풀어가다보니 마침내 이른 형태가 샘플들의 선형 합입니다. (제곱, log 등 별 희안한 조합이 뒤섞인 형태일 수도 있었는데 말이죠) 여기서 "some"이라 굳이 강조한 이유는 경계에 걸친 샘플들 외에는 $\alpha$ 값들이 0이기 때문입니다.
결국 $\alpha$ 값만 알게 되면 $\vec{w}$를 구할 수 있게 되었습니다. 그럼 이제 여기서 얻은 식들을 이용해서 \eqref{eq:4}에 대입하여 $\alpha$에 대한 식으로 바꾸고 문제를 더 단순화 해보겠습니다. 식 \eqref{eq:4}에서 두번째 항의 $-1$ 부분을 밖으로 꺼내고 식\eqref{eq:b}을 이용하여 $b$ 부분을 없앨 수 있습니다. 이어 식 \eqref{eq:w}을 이용하여 $\vec{w}$를 대신 넣어주면 다음과 같이 정리가 가능합니다:
\begin{align*} \sum_{i=1}^N \alpha_i + \frac{1}{2}||\vec{w}||^2-\sum_{i=1}^N\alpha_iy_i\vec{w}^T\vec{x}_i
&\iff \sum_{i=1}^N \alpha_i + \frac{1}{2}\vec{w}^T\vec{w}-\vec{w}^T \vec{w} \\
&\iff \sum_{i=1}^N \alpha_i - \frac{1}{2}\vec{w}^T \vec{w} \\
&\iff \sum_{i=1}^N \alpha_i - \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_j y_iy_j\vec{x}_i^T\vec{x}_j\\
&\iff \cal{L}(\alpha).
\end{align*}
따라서 이제 모든 것이 $\alpha$에 대한 maximization 문제로 정리가 끝났습니다. 이 문제를 풀어 $\alpha$를 구하면, 식 \eqref{eq:w} $\vec{w} = \sum_i\alpha_iy_i\vec{x}_i$을 사용해서 $\vec{w}$를 구할 수 있게 되고 이어 식 \eqref{eq:2}을 통해 $b$도 구할 수 있게 됩니다. 식 \eqref{eq:2}에 의해 $\alpha$ 값이 0이 아니라는 것은 해당 $\vec{x}$가 경계선을 정하는 샘플이라는 뜻이고 SVM에서는 이런 샘플들을 "support vector"라고 부릅니다.

"support vectors"
오 그런데 전개를 하고 보니 $\cal{L}(\alpha)$ 식은 매우 좋은 성질을 갖고 있습니다. $\alpha$에 대해 첫째 항은 선형이고 둘째 항은 quadratic이기 때문에 quadratic programming 테크닉을 사용하여 어떠한 off-the-shelf 알고리즘이든 사용하면 $\alpha$ 해를 구할 수 있습니다.
즉, 이 SVM은 신경망과는 달리 local minima에 빠질 걱정을 전혀 하지 않아도 된다는 것이죠. 따라서 SVM으로 구한 해는
"언제나 (현재 SVM이 줄 수 있는) 최적의 해라는 것이 이론적으로 보장"
됩니다 (소름!).
따라서 support vector들로 정해진 decision boundary가 가장 최적의 boundary이며, 현재 가지고 있는 데이터만으로 새로운 샘플이 들어왔을 때 일반화를 가장 잘 할 수 있는 decision rule을 찾을 수 있게 된 것입니다.
(bonus) The way to Kernel trick
짠! 우리는 이제 SVM에 대한 큰 줄기를 모두 훑었습니다. 재미있는 사실은 SVM과 관련된 핵심 수식들이 모두 샘플에 대한 "내적"으로 이루어져 있다는 것입니다. $\cal{L}(\alpha)$ 식에서 $\vec{x}_i^T\vec{x}_j$ 부분이 그러하고 우리가 decision rule로 정의하였던 식 \eqref{eq:dr} 역시도 식 \eqref{eq:w}을 대입하여 바꿔주면 결국 $\vec{x}\cdot\vec{u}$과 같이 sample과 모르는 unknown 샘플의 내적에 따라 값이 바뀌는 것을 보실 수 있습니다.
왜 갑자기 내적을 강조하는지 의아하실 수 있는데요 지금까지 소개한 SVM은 우리가 흔히 아는 Euclidean 공간에서의 내적을 사용하고 있었습니다. 그런데 샘플들이 살고 있는 공간이 매우 복잡하여 두 샘플 간의 거리를 가늠할 때 단순한 내적을 사용하는 것이 맞지 않는 경우가 있을 수 있습니다. (사실 대다수의 흥미로운 문제들은 그렇죠) 즉, 샘플들이 linearly separable한 경우라면 지금까지 본 SVM이 매우 잘 동작하지만 그게 아닌 경우는 문제를 전혀 풀지 못하는 문제가 생기게 됩니다.
바로 이 부분에서 재미있는 아이디어들이 많이 나옵니다. 현재 샘플이 살고 있는 공간에서 샘플 군간의 구별이 어렵다면, 어떤 함수 $\phi(\cdot)$을 잘 디자인하여 샘플들이 linearly separable한 공간으로 샘플들을 보내준 후 그 공간에서의 SVM을 적용하는 것을 생각해볼 수 있습니다.
이를 심지어는 무한 차원을 갖는 어떤 feature space로 확장하여 생각을 해볼 수 있는데요. 이 경우 매우 큰 차원이 갖는 풍부한 표현력을 이용하면서도 실제 decision boundary에 영향을 주는 support vector들은 상대적으로 매우 적을 수 있기 때문에 일반화를 매우 잘 하는 모델을 세울 수 있게 됩니다.
다만 $\phi(\cdot)$이라는 무한 차원으로 보내줄 적절한 함수를 찾는 것도 쉬운 일은 아닐테죠. 그런데 잘 생각해보면 SVM을 적용할 때 우리가 필요한 것은 사실 그 차원으로 보내는 함수가 아니라 그 공간에서의 내적값입니다. 즉, 만약 어떤 Kernel이 있어서 우리가 $K(\vec{x},\vec{y}) = \phi(\vec{x})\cdot\phi(\vec{y})$와 같이 우연히도 다른 공간에서의 내적값에 대응하는 값을 주는 녀석을 잘 디자인할 수 있다면 non-linearly separable한 경우에 있어서도 SVM이 잘 작동할 수 있을 것입니다.
이게 제가 이해하고 있는 Kernel trick의 흐름입니다. 아마 기회가 된다면 다음 번 글에서 앞서 자세히 소개하지 못한 최적화 부분 얘기와 함께 내용을 다룰 수 있지 않을까 싶습니다.
마무리
이 글을 쓰기 위해 Patrick Winston 교수님의 MIT OCW 강의를 듣다 멈추다 하며 정리를 하다보니 오히려 더 배웠습니다. SVM이라는 방법론이 나오게 된 이유부터 문제 설정, 문제를 풀기 위해 필요한 요소들을 하나하나 만들어 나가는데, 별다른 강의 자료 하나 없이 그리고 복잡한 수식 따위 없이 분필 하나만을 쥐고서 처음과 끝은 잇는 커다란 흐름에 따라 칠판에 차근차근 논리를 전개하는 50분의 강의는 버릴 프레임이 단 한 프레임도 없습니다.
매우 단순하고 명료한 논리를 따라가다보면 모든 수식이 모자람도 덜어낼 것도 없이 딱 필요한만큼 당연히 있어야 할 자리에 있을뿐 전혀 어렵지 않게 설명이 가능하다는 것을 알 수 있습니다. SVM이라는 키워드에 같이 따라오는 여러 수식들 때문에 두려움이 있었던 분들께 이 강의를 다시 한 번 강력히 추천합니다.
영상을 보기에는 아직 부족하지만 영상도 보고 이해가 안되는 부분이 있어 쓰신 글을 봤는데 큰 흐름을 잡는 데 도움이 된 것 같습니다.
답글삭제한가지 질문이 있는데 글에서 라그랑지 승수법을 쓰신 부분에 minimize와 maximize부분이 있는데 어떤식을 minimize고 maximize인지 알 수 있을까요? 아직 이해가 부족해서 이런 부분에서도 막히네요 ㅠㅠ
밑에 w.r.t(with respect to)로 설명이 되어 있는데요...
삭제좋은 글 잘 보고갑니다. 수식적 전개가 주는 인사이트를 알려주셔서 감사합니다.
답글삭제궁금한게 있는데 제가 배웠을적에 svm 유도 수식은 Cost function기반 bias-variance trade-off 를 할 수 있는것으로 알고있는데요.
해당 수식에서 Cost function을 어떻게 다루는지 알고싶습니다.
다시와서보니 제가 무지했었네요. Cost Function으로 trade off 조정하는건 soft-margin 기법인데 말이죠. alpha에 대한 최적화 문제로 치환되는것이 맞네요!
삭제⟺∑i=1Nαi−∑i=1N∑j=1Nαiαjyiyjx⃗ Tix⃗
답글삭제여기에서 2번째 sigma에 1/2 곱해져야 하는것 아닌가여..?
앗 넵 맞습니다. 감사합니다 :)
삭제혹시 어떤 책으로 공부하시나요?
답글삭제Unknown님 안녕하세요. 답변이 매우 늦었지만 달아보자면, 음 딱히 책을 보면서 공부하지는 않습니다. 궁금한 것을 인터넷에서 찾아보면서 자료를 찾고 읽거나 영상을 보는 식으로 공부합니다ㅎ
삭제죄송합니다만, 3번 수식에서 4번 수식으로 전개된 과정이 이해가 안되는데,, 알려주실수 있을까요 거리 공식 구하는것 같은데,, 가물가물 하네요
답글삭제Woong님 안녕하세요. 그냥 단순한 대입입니다. x+에 대응하는 y는 1이고 x-에 대응하는 y는 -1므로 yi(w xi + b) = 1 식에 대입하셔서 wx+와 wx-를 좌변에 두고 우변으로 나머지를 모으면 wx+ = 1-b wx- = b-1 이므로 둘을 빼면 2가 나옵니다. 이해에 도움이 되셨을까요?
삭제좋은 글 감사합니다.
답글삭제그런데, 최종적으로 (학습데이터로부터? 서포트 벡터로부터?) 알파값을 어떻게 구한다는 것인지 이해가 안됩니다.
위의 (bonus) The way to Kernel trick를 얘기하기 직전의 내용을 말하는 것입니다.
지나가다가 대신 답변드립니다.
삭제알파값을 구하는건 또다른 이슈입니다. 알파가 들어간 maximization 문제는 처음문제의 dual form이라고 부르며, quadratic programming으로 풀 수 있는 문제입니다. 그리고 quadratic programming을 푸는 많은 테크닉이 따로 존재합니다.
사실 원래문제였던 min(|w|^2/2)구하기도 quadratic programming으로 풀 수 있는 문제입니다. 그런데 라그랑주승수법을 사용해 굳이 dual form으로 변형한 주 이유는 kernel trick을 사용하기 위함입니다. dual form에는 샘플 x들끼리의 '내적'이 포함되어있지만 원래문제에는 그렇지 않기 때문이에요.
좋은글 감사합니다. 잘보구 갑니다~~
답글삭제Unknown님 감사합니다 :) 도움이 되셨다면 다행이네요 ㅎ
삭제제일 처음에 decision rule 설정 하실때에, '최소한 1보다는 큰 값을 주도록 해본 것입니다.'라고 하셨는데, 이게 하필 1인 이유가 있나요?
답글삭제아니요 딱히 없습니다ㅎ 이해를 돕기 위해 일반적으로 normalize하여 1이라고 생각하셔도 되구요.
삭제좋은 글 너무 감사합니다!
답글삭제안녕하세요! 덕분에 SVM 과 조금 더 친해졌습니다. 그런데 혹시 식 2, 3, 5 에서 \omega 가 \omega^T 로 바뀌어야하는 것이 아닌가요?
답글삭제많은 도움이 되었습니다. 정말 감사합니다!
답글삭제alpha 값을 구하는 방법 가운데 cross validation을 통해 구하는 방법이 있습니다.
답글삭제좋은 글 감사합니다. 덕분에 많은 도움이 되었습니다.
답글삭제