 Korean
Korean English
EnglishNIPS 2016에서 가장 hot한 키워드를 하나 꼽으라 한다면 Generative Adversarial Network(GAN)이라고 단언할 수 있을 정도로 2014년에 Ian Goodfellow(이름 한 번 독특하네..웬만해서는 이름 쉽게 못 외우는데 한 번에 외웠네요 좋은 친구라니 ㅋㅋ)가 NIPS에서 발표한 paper에서 시작한 GAN 붐은 2016년에 더 크게 터진 것 같습니다.
과연 facebook의 Yann Lecun 교수님이 근 10-20년 간에 기계학습 나온 아이디어 중 최고라고 할만하구나(근데 너무 자주, 여러 번, 모든 곳에서 얘기하시는 듯...뭐..그만큼 중요하단 얘긴가...)란 느낌이 들 정도로 이미지 생성(image generation) 외에도 natural language processing(NLP) 등 다양한 분야에서 엄청난 성과들을 보여주고 있습니다.
당장 TensorFlow나 MatConvNet으로 GAN을 구현해서 뭔가 좀 더 새로운 것을 해내야...졸업을 시작?할 수라도 있을 것 같은 불쌍한 대전의 대학원생은 일단 GAN에 대해 또 열심히 공부를 하기 시작했고...orz... 그 일환으로 Ian Goodfellow의 NIPS 2014 paper를 나름대로 정리해 보았습니다.
이 paper에서 중요한 내용은 크게 두 가지로 나눌 수 있을 것 같습니다;
- GAN에 대한 이론적 개념 제시(minimax problem)와
- GAN이 풀어야하는 problem이 global minimum에서 unique solution을 갖고 어떤 조건을 만족하면 해당 solution으로 수렴한다는 것을 증명.
[GAN에 대한 개념적 소개]
GAN은 이름만 뜯어봐도 일단 큰 줄기를 알 수 있습니다.
"Adversarial"이란 단어의 사전적 의미를 보면 대립하는, 적대하는 란 뜻을 갖습니다. 대립하려면 어찌 되었든 상대가 있어야하니 GAN은 크게 두 부분으로 나누어져 있다는 것을 먼저 직관적으로 알 수 있죠.
뭔가 Image를 만들어내는 녀석과(Generator) 이렇게 만들어진 녀석을 평가하는 녀석(Discriminator)이 있어서 서로 대립(Adversarial)하며 서로의 성능을 점차 개선해 나가자는 것이 주요 개념입니다.
Ian Goodfellow가 본문에서 예시로 든 것은 지폐위조범과 경찰인데 나름 재미있기도 하고 이해가 잘 되어 여기에 소개해보겠습니다.
지폐위조범(Generator)은 경찰을 최대한 열심히 속이려고 하고 다른 한편에서는 경찰(Discriminator)이 이렇게 위조된 지폐를 진짜와 감별하려고(Classify) 노력한다.
이런 경쟁 속에서 두 그룹 모두 속이고 구별하는 서로의 능력이 발전하게 되고 결과적으로는 진짜 지폐와 위조 지폐를 구별할 수 없을 정도(구별할 확률 $p_d=0.5$)에 이른다는 것.
이런 경쟁 속에서 두 그룹 모두 속이고 구별하는 서로의 능력이 발전하게 되고 결과적으로는 진짜 지폐와 위조 지폐를 구별할 수 없을 정도(구별할 확률 $p_d=0.5$)에 이른다는 것.
아 정말 이해가 잘 돼...내가 이런 예화를 논문에 쓴다 그러면 우리 교수님은 장난치는거냐고 하실지도...-_- 교수님은 언제나 진지하시니까ㅋㅋ Ian Goodfellow는 논문을 정말 이해가 잘 되도록 쓰는 능력이 있는 듯 합니다. 다른 논문들도 다 글이 쉽고 수학도 그리 어렵지 않고 친절해..
아무튼 이런 예시를 좀 더 딱딱하게 수학적인 용어를 섞어 쓰면 다음과 같습니다. Generative model $G$는 우리가 갖고 있는 data $x$의 distribution을 알아내려고 노력합니다. 만약 $G$가 정확히 data distribution을 모사할 수 있다면 거기서 뽑은 sample은 완벽히 data와 구별할 수 없겠죠.
한편 discriminator model $D$는 현재 자기가 보고 있는 sample이 training data에서 온 것(진짜)인 지 혹은 $G$로부터 만들어진 것인 지를 구별하여 각각의 경우에 대한 확률을 estimate합니다.

* 그림은 Ian Goodfellow가 최근 arXiv에 올린 NIPS 2016 Tutorial: Generative Adversarial Networks에서 가져왔습니다. 다음 번 글에서는 이 튜토리얼을 쭉 다뤄볼까 싶기도 한데 워낙 소개하는 양이 방대해서 여유가 되면 하는 것으로..ㅎㅎㅎ
따라서 위 그림을 보면 알 수 있듯이 $D$의 입장에서는 data로부터 뽑은 sample $x$는 $D(x)=1$이 되고, $G$에 임의의 noise distribution으로부터 뽑은 input $z$ 넣고 만들어진 sample에 대해서는 $D(G(z))=0$가 되도록 노력합니다. 즉, $D$는 실수할 확률을 낮추기(mini) 위해 노력하고 반대로 $G$는 $D$가 실수할 확률을 높이기(max) 위해 노력하는데, 따라서 둘을 같이 놓고보면 "minimax two-player game or minimax problem"이라 할 수 있겠습니다.
여기서 잘 보면 알겠지만 $G$와 $D$는 사실 꼭 neural network로 만들 필요가 없습니다. 어떤 model이든 이 역할을 서로 "잘" 해줄 수만 있다면 상관이 없습니다만 neural network를 사용한 것이 여러모로 실제 적용시 여러 장점이 있기에(물론 단점도 있지만) 그리고 결과도 꽤 잘 나오기에 결국 Generative Adversarial Nets가 된 것으로 보입니다.
어떤 장단이 있고 "잘"하는 것이 어떤 의미인지는 나중에 소개하겠습니다.
[Adversarial Nets]
일단 $G$와 $D$가 둘 다 multilayer perceptrons model을 사용하면..Generator's distribution $p_g$ over data $x$를 학습하기 위해 generator의 input으로 들어갈 noise variables $p_z(z)$에 대한 prior를 정의하고, data space로의 mapping을 $G(z;\theta_g)$라 표현할 수 있습니다. 여기서 $G$는 미분 가능한 함수로써 $\theta_g$를 parameter로 갖는 multilayer perceptron입니다.
한편, Discriminator 역시 multilayer perceptron으로 $D(x;\theta_d)$로 나타내며 output은 single scalar 값이 되겠다(확률이므로). $D(x)$는 $x$가 $p_g$가 아닌 data distribution으로부터 왔을 확률을 나타냅니다.
따라서, 이를 수식으로 정리하면 다음과 같은 value function $V(G,D)$에 대한 minimax problem을 푸는 것과 같아집니다;
$$\min_G \max_D V(D,G) = \mathbb{E}_{x\sim p_{data}~(x)}[log D(x)] + \mathbb{E}_{z\sim p_x(z)}[log(1-D(G(z)))]$$
뭐든지 간에 이런 수식이 있으면 극단적인 예시를 넣어 이해하는 것이 빠르죠. 먼저 가장 이상적인 상황에서의 $D$ 입장을 생각해 보겠습니다.
$D$는 아주 잘 구별을 하는 녀석이므로 $D$가 보는 sample $x$가 실제로 data distribution으로부터 온 녀석이라면 $D(x) =1$이므로 첫번째 term에서 $log$ 값이 사라지고 $G(z)$가 만들어낸 녀석이라면 $D(G(z))=0$이므로 두 번째 term 역시 0으로 사라지죠. 이 때가 $D$의 입장에서 $V$의 "최대값"을 얻을 수 있다는 것은 자명합니다.
반대로 $G$의 입장에서 생각해봐도 상황은 비슷합니다.
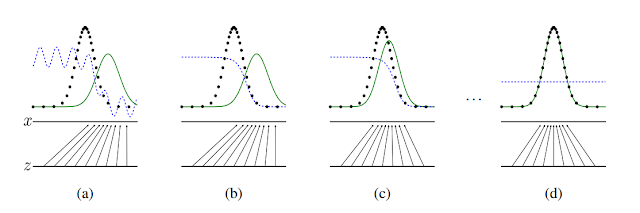
이 그림은 본 논문(NIPS 2014)에서 빌려왔습니다. 위에 설명한 내용을 아주 이해하기 좋게 잘 그려놓았는데 부연을 좀 하자면, 먼저 검은 점선이 data generating distribution, 파란 점선이 discriminator distribution, 녹색 선이 generative distribution이다. 밑에 $s$와 $z$선은 각각 $x$와 $z$의 domain을 나타내며, 위로 뻗은 화살표가 $x=G(z)$의 mapping을 보여줍니다.
즉, 처음 시작할 때는 (a)와 같이 $p_g$가 $p_{data}$와 전혀 다르게 생긴 것을 볼 수 있고 이 상태에서 discriminator가 두 distribution을 구별하기 위해 학습을 하면 (b)와 같이 좀 더 smooth하고 잘 구별하는 distribution이 만들어집니다. 이후 $G$가 현재 discriminator가 구별하기 어려운 방향으로 학습을 하면 (c)와 같이 좀 더 $p_g$가 $p_{data}$와 가까워지게 되고......
이런 식으로 쭉 학습을 반복하다 보면 결국에는 $p_g = p_{data}$가 되어 discriminator가 둘을 전혀 구별하지 못하는 즉, $D(x)=\frac{1}{2}$인 상태가 된다는 것이죠.
논문에서 한 가지 실용적인 tip이 나오는데, 위에 value function에서 $log(1-D(G(z)))$ 부분을 $G$에 대해 minimize하는 대신 $log(D(G(z)))$를 maximize하도록 $G$를 학습시킨다는 것입니다.
나중에 저자가 밝히 듯이 이 부분은 전혀 이론적인 동기로부터 수정을 한 것이 아니라 순수하게 실용적인 측면에서 적용을 하게 된 것이라 합니다.
이유도 아주 직관적인데 예를 들어 학습 초기를 생각해보면, $G$가 초기에는 아주 이상한 image들을 생성하기 때문에 $D$가 너무도 쉽게 이를 real image와 구별하게 되고 따라서 $log(1-D(G(z)))$ 값이 매우 saturate하여 gradient를 계산해보면 아주 작은 값이 나오기 때문에 학습이 엄청 느립니다.
하지만 문제를 $G = arg\max_G log(D(G(z)))$로 바꾸게 되면, 초기에 $D$가 $G$로 나온 image를 잘 구별한다고 해도 위와 같은 문제가 생기지 않기 때문에 원래 문제와 같은 fixed point를 얻게 되면서도 stronger gradient를 줄 수 있는 상당히 괜찮은 해결방법이죠.
[Theoretical Results]
앞서 말했던 두 가지 주요 내용 중 두 번째 부분입니다.
이 부분도 크게는 두 가지로 나뉘는데 먼저, 앞서 소개한 minimax problem이 $p_g = p_{data}$에서 global optimum을 갖는다는 것을 보이고 이어서 이 논문에서 소개하는 알고리즘이 global optimum을 찾는다는 것을 보이겠습니다....만,
일단 이건 다음 글에서....ㅎㅎ 이 부분도 사실 너무 쉽게 잘 설명되어 있어서 리뷰할 필요가 있나 싶네요...글이 너무 길어지는 것 같아....누가 읽기나 하려나....
다음 읽을거리
참고문헌:
[1] Generative Adversarial Nets - Ian Goodfellow et al. 2014 논문,
[2] NIPS 2016 Tutorial: Generative Adversarial Networks
이 부분도 크게는 두 가지로 나뉘는데 먼저, 앞서 소개한 minimax problem이 $p_g = p_{data}$에서 global optimum을 갖는다는 것을 보이고 이어서 이 논문에서 소개하는 알고리즘이 global optimum을 찾는다는 것을 보이겠습니다....만,
일단 이건 다음 글에서....ㅎㅎ 이 부분도 사실 너무 쉽게 잘 설명되어 있어서 리뷰할 필요가 있나 싶네요...글이 너무 길어지는 것 같아....누가 읽기나 하려나....
다음 읽을거리
- 초짜 대학원생 입장에서 이해하는 Generative Adversarial Nets (2)
- [PR12-Video] 1. Generative Adversarial Nets (동영상 설명)
- GAN: 카카오 리포트 기고문 (part I) (part II)
- 초짜 대학원생의 입장에서 이해하는 Domain-Adversarial Training of Neural Networks (DANN) (1)
- Gaussian Distributions are Soap Bubbles, inFERENCe 2017. 11. 09.
- 박스 안에 넣은 공의 지름이 박스보다 클 때
- 공이 점점 비눗방울처럼 변할 때 (When ball becomes a soap bubble)
참고문헌:
[1] Generative Adversarial Nets - Ian Goodfellow et al. 2014 논문,
[2] NIPS 2016 Tutorial: Generative Adversarial Networks
바쁘다는 핑계로 초록만 읽어봤던 논문이었는데, 이렇게 한글로 설명을 해주시니 정말 도움이 되었습니다. 감사합니다.
답글삭제Techmania님 안녕하세요 댓글 감사합니다. 도움이 되셨다니 다행입니다 :)
삭제감사합니다. 앞으로도 많이 올려주세요! 혹시 tf로 예제코드는 짜실 계획은 있으신가요?
답글삭제안녕하세요 Unknown님 댓글 감사합니다. 1D에 대해 toy code를 돌려보긴 했었습니다. 시간이 된다면 예제코드 짠 것을 간단한 설명이랑 올려볼까요 ㅎㅎ
삭제이제 막 머신러닝 시작하는 초보인데, 영어가 약해서 분석이 잘 안되던 부분을 덕분에 잘 이해하고 갑니다. 올리시는 포스트 잘 보고 있습니다. 감사합니다!
답글삭제안녕하세요 Prosik님 댓글 감사합니다. 저도 초보라 ㅎㅎ 도움이 되셨다니 다행입니다.
삭제감사합니다. 해당사항에 대해 공부를 하던 학부연구생인데 큰 도움이 됩니다
답글삭제Unknown 님 안녕하세요. 댓글 감사합니다. 도움이 되셨다니 다행이네요 ㅎㅎ
삭제혹시 log(1 - D(G(z))를 미분했을 때 왜 작은 gradient 값이 발생하는지 좀 더 구체적으로 설명해주실 수 있으신가요?
답글삭제안녕하세요. 초기에 G가 제대로 이미지를 생성 못할 때는 D가 구별하기 매우 쉽기 때문에 거의 항상 0값을 내놓은다고 생각해보시면 왜 그런지 알 수 있습니다. log 안에 값이 항상 1에 가깝고 그 주변에서 gradient도 매우 작죠.
삭제많이 배우고 갑니다. GAN 관련해서 알송달송했었던 부분이 있었는데, 읽다보니 안개가 사라지는 느낌입니다.
답글삭제Unknown님 안녕하세요 도움이 되셨다니 다행입니다 :)
삭제안녕하세요. p_data(x) : data distribution 이 정확히 어떤 의미인가요? "unknown data generating distribution"라는데 무엇에 대한 확률분포인지 혹시 좀 쉽게 설명해주실수있으신가요?
답글삭제안녕하세요 metamath님. 실제 이미지들의 분포를 말합니다. 이미지들이 어떤 분포를 가지고 있는지 알 수 있다면 그 분포에서 sample을 뽑을 수도 있겠죠.
삭제작성자가 댓글을 삭제했습니다.
삭제답변 감사합니다.
삭제심볼이 p라서 어떤 확률분포가 아닐까 했는데..다시보니 확률이란 말은 없는것같네요. 확률분포라면 무엇의 확률분포인가 하는 생각이 들어서 질문드린것이었는데...
앞에 기대값이 있는것으로 봐서 x는 이미지를 표현하는 랜덤변수고 p는 그 랜덤변수의 확률분포를 나타내는것이 아닐까요?..그냥 그런생각이 들어서 한번 질문드려봅니다.
어 질문이 하나 더 달린 것을 몰랐습니다. 답변이 늦어 죄송합니다. 확률 분포가 맞습니다. 이미지들이 샘플인 확률 분포입니다.
삭제안녕하세요 저도 저 distribution의 의미를 잘 몰라서 여쭤볼게요~
삭제이미지들의 분포라는 말이 어떤 의미를 갖는지 잘 몰라서 혹시나 조금 더 설명을 부탁드려도 될까요?? 그리고 실제 이미지들의 분포가 위의 그림처럼 항상 정규분포가 되어야 하는 것은 아닌거죠?? 여기서는 그냥 예시인가요??
기완님 안녕하세요. 네 맞습니다. 예시이지요. 1차원에 대해 그냥 분포가 가장 익숙한 모양이 하필 저 모양이었을뿐입니다. 이미지라는 것을 픽셀개수만큼의 차원수를 지닌 vector라고 생각하면 결국 high dimentional 좌표에 있는 점으로 생각하실 수 있고 이런 점들이 분포한 모양을 정의할 수 있겠죠.
삭제논문의 수식 (1)에서 value function V(G,D)에서 Ex~pdata 의 E는 무슨 의미일까요?. 확률인가요,,..
답글삭제확률이라고 생각했는데 수식(5) 위에 Ex~pdata(-log2)+Ex~pg[-log2]=-log4 로 합쳐지는 부분을 보니 이해가 안가네요...
음 expectation 한국말로는 기대값입니다. 간단하게는 mean으로 생각하셔도 되겠네요.
삭제Iangoodfellow 이름 정말 특이하죠 ㅎㅎ
답글삭제글 잘 보고있습니다.
감사합니다
안녕하세요 Youngjae Jin님ㅎ 도움이 되셨다니 다행입니다 ㅎㅎ이제는 하도 봐서 저절로 외워졌습니다.
삭제잘 보고 갑니다. 학부연구생인데 배워가는게 많습니다 ㅎㅎ
답글삭제질문있습니다
위의 value function 에 대해서 결국 ideal한 조건에서 V(D,G)=0 으로 만드는게 알고리즘의 최종 목표인건가요? (D(x)=1/2로 만드는걸 의미하는게 맞나요??)
웹상에서 앤드류응 교수님 코세라 강의듣고 이것저것 찾아보면서 맨땅에 헤딩하는데 유재준님 블로그가 굉장히 정리 잘 되어있어서 맨날맨날 들어오면서 공부하고 있습니다 ㅎㅎ
저는 현재 generative adversarial text to image synthesis 논문에 관심있어서 공부하기위해서 gan을 먼저 공부하고 있습니다! 혹시 관련하여서 추천할만한 사이트나 글 있으면 조언 부탁드립니다 :)
블로그 글에 항상 감사드립니다!ㅎㅎ
Unknown님 댓글 감사합니다. 이걸 왜 못보고 지나갔는지 모르겠네요. ideal 조건에서는 V(D,G)가 -log4가 나올 것입니다. 제가 다른 사이트를 잘 알지는 못하네요 혹시 알게되면 또 댓글 달겠습니다.
삭제눈에 확 들어오는 글이네요.
답글삭제잘 읽고 갑니다.
재준님과 같은 분들 때문에 우리나라 ML가 많이 발전하겠네요.
Unknown님 댓글 감사합니다. 저도 공부하는 중이라 한글로 설명해주는 곳이 있었으면 좋겠다고 투덜거리다 스스로 만들기 시작했네요 그렇게 칭찬해주시니 보람있습니다ㅎㅎ
삭제작성자가 댓글을 삭제했습니다.
답글삭제안녕하세요. 작성하신 글과 동영상 보면서 GAN공부하는데 도움이 많이 되고 있습니다 :).
답글삭제실례지만 질문하나만 해도될까요?
R로 GAN을 구현하는 중인데, D와 G를 번갈아가면서 위 식에서
언급한 대로 학습을 하게 하려고 하는데요.
D의 경우, log(D(X))+log(1-D(G(z))를 maxmize하도록
gradient ascent 방식을 통해 학습을 하게 하였습니다.
10회 정도 반복하면, D(x)는 1에 가까워지고
D(G(z))는 0에 가까워지게 됩니다.
(일단 여기까지는 잘된게 맞는거겠죠? GAN의 global optimal은 p(data) = p(G) = 1/2이 되도록하는 지점인데, 이는 D와 G가 번갈아가면서 학습하면서 최종적으로 다달아야하는 지점인걸로 이해했는데.
맞는건가요?)
우선 D에 대하여 P(x) = 1, P(g) = 0이 되도록 학습한후,
G에 대해서 학습을 시키는데, 여기서 계속 문제가 발생하는 것 같습니다.
(2주째 R만 건드리는 중이네요ㅠㅠㅠ)
G의 Loss function을 log(D(G(Z))로 정의하고, 이를 maxmize하도록 학습하는 거라면, D(G(Z))는 1에 가까워지게 됩니다.
그런데 여기서 제가 드는 의문은, 그럼 D(X)는 어떻게 되야하는거지?
라는 것입니다. global optimum이 p(x)=p(g)=1/2이라고 한다면,
G를 학습하는 과정에서 D(G(Z))가 0에서 1로, D(X)가 1에서 0으로 가까워지게 되어야 하는 것 같은데. 위 LOSS function만 본다면, X에 대하여 D(X)가 0이 되도록하는 부분이 보이지 않아서요 ㅠㅠ
G의 weight를 업데이트 하기 위해서는 D(G(Z))의 에러에서부터 Delta값을 구해와야하기 때문에, G의 gradient를 구하는 과정에서 D의 gradient도 구할수 있긴 합니다. 현재 제가 구현해 놓은 모델은 여기서 구한 D의 weight를 업데이트 시키지 않고 G의 weight만 업데이트 시켜놓았습니다. 이렇게 되면 처음 D를 학습하면서, P(x)=1, P(G(Z))=0이 된 상황에서 G를 학습시키면서 P(X)=1는 바뀌지 않고 P(G(Z))가 1에 가까워 지게 됩니다. G를 학습시키는 도중에 D의 weight도 업데이트 시켜줘야하는건가요??(제 코드에선 D의 weight를 업데이트시키면 발산해버립니다.ㅠㅠㅠ 이건제가 잘못짠거겠죠ㅠㅠ)흙
해결했습니다 : ) 제가 짰던 코드에서 batch를 추가적으로 넣어주니 제대로 생성을 해내는군요 :)
답글삭제해결하셨다니 다행입니다 답변이 늦어 죄송합니다 :)
삭제Ex∼pdata (x)[logD(x)]+Ez∼px(z)[log(1−D(G(z)))]
답글삭제이 부분에서요 x~pdata 가 의미하는게 뭔가요?.... E는 에러를 의미하는건가요....
안녕하세요 동욱님. E는 기대값 expectation을 나타내는 것으로 확률과 통계에서 나오는 notation입니다. 이 때, x라는 값이 따르는 분포를 알려줘야하는데 이를 x~p_data 라고 나타냅니다. 즉, 여기서는 x가 p_data라는 분포에서 나왔다는 것을 얘기합니다.
삭제논문을 읽다 이해가 잘 안되어 찾게 되었습니다. 정리가 너무 잘되어 있어서 감사합니다. 부럽네용 ㅠ
답글삭제안녕하세요 찬식님. 어떤 점이 부러우실까요 ㅋㅋ 저도 한글이 없어서 그렇지 찬식님처럼 블로그도 찾아보고 그러면서 이해했습니다 :)
삭제작성자가 댓글을 삭제했습니다.
답글삭제value function V(G, D) 수식에서 z의 distribution 에 대한 notation에서 z~p_x(z)가 아니라 z~p_z(z) 같은데요...
답글삭제좋은 글 항상 잘 보고 있습니다 ㅎㅎ 저도 수학을 잘 모르는 분들이 쉽게 접근할 수 있도록 글을 함 써봤네요 ㅎ 틀린 내용이 있으면 알려주세요~! https://dl-ai.blogspot.kr/
답글삭제좋은 글 고맙습니다.
답글삭제구글링중 정말 흥미있는 내용이였던 GAN였는데 이렇게 친절한 설명이라니 감사합니다
답글삭제우인수님 안녕하세요 도움이 되셨다니 다행입니다!
삭제감사합니다. 잘Ian Goodfellow씨처럼 쉽게 쓰셔서 잘 읽고 갑니다!
답글삭제Unknown님 안녕하세요. 도움이 되셨다니 다행입니다!
삭제잘보고 갑니다^^
답글삭제Unknown님 안녕하세요. 감사합니다 :)
삭제항상 박사님 글 잘 읽고있는 석사생입니다! 감사합니다 ㅎㅎ
답글삭제Unknown님 안녕하세요. 제 글을 읽어주셔서 감사합니다 :)
삭제감사합니다. 덕분에 본 논문에 대한 세미나를 무사히 진행했습니다.
답글삭제성일님 도움이 되셨다니 다행입니다.
삭제안녕하세요. 혹시 이미지의 확률분포란게 무엇인지 알 수 있을까요?
답글삭제x축과 y축이 뜻하는 개념이 감이 안오네요.
input image가 64x64x3이라면
x축이 x1부터 x(64x64x3) 총 12000개정도가 쭉 나열된 것인지,
아니면 이미지 데이터 셋이 1000개라면
x1부터 x1000까지 각 이미지를 쭉 나열한 것인지 이해가 안가네요.
확률이라고 하면 y는 뜻하는게 뭘까요?ㅠㅠ
안녕하세요 Unknown님 이미지를 하나의 vector로 생각하면 그런 이미지들이 살고있는 vector space를 생각할 수 있죠. 그리고 각 이미지마다 해당 vector space에서 sampling 했을 때, 나올 확률이 있을겁니다. (natural image의 확률 분포가 무엇인지는 모를지언정 존재한다고 생각하면 말이죠.) 이런 뜻에서의 확률 분포를 말하는겁니다.
삭제안녕하세요. GAN모델을 보고 궁금한게 있어서 질문드립니다.
답글삭제G와 D의 Loss율에 대한 것인데요... 수식을 정확히 이해를 못해서 그런데
G의 Loss율은 높아져야 좋은것이고 D의 Loss율은 점점 0에 수렴해야 좋은것인가요??
흥미로운데요? 잘 읽고갑니다.
답글삭제교수님 감사합니다~^^
답글삭제Unknown님 안녕하세요. 감사합니다 :)
삭제유니스트 AI 대학원에서 GAN을 공부중인 학생입니다. 감사합니다 교수님.
답글삭제앗 그러시군요. 반갑습니다ㅎ 도움이 되었으면 좋겠네요 :)
삭제안녕하세요. 글 잘 읽었습니다!
답글삭제궁금한 부분이 있습니다만 혹시 loss function에서의 min-max를 뒤집으면 어떠한 결과물이 예상되는지 알 수 있을까요? 스스로 상상이 잘 안되어서 질문드립니다.
Unknown님 안녕하세요. 좋은 질문입니다. 사실 그 부분이 고질적인 문제인데요. 이에 대해서는 다음 읽을거리들로 걸어둔 링크들 중 "GAN: 카카오 리포트 기고문" part2 (https://jaejunyoo.blogspot.com/2019/05/part-i.html)를 보시면 마지막 쯤에 "GAN 학습이 어려운 이유 II: Mode Collapse"이라는 내용으로 좀 더 다루고 있습니다.
삭제