 Korean
Korean English
English오늘은 딱딱한 논문 대신 Andrew Ng 교수님이 NIPS 2016에서 발표하신 튜토리얼을 좀 정리해보겠습니다.
이 글은 원래 영어로 먼저 정리를 해서 올렸는데 음...블로그를 bilingual로 운영해보고자 하는 원대한 꿈을 가지고 시작했으나... ㅋㅋㅋ 한국어를 기본으로 하되 제가 시간이 되거나 중요하다 싶은 내용만 영어로 번역하는 것으로 방침을 급선회하였습니다.
아무튼..오늘 애기할 강의는 NIPS 2016 홈페이지에서도 공식 영상을 제공하지는 않지만 비슷한 때에 같은 제목에 내용을 애기한 영상이 유튜브에 있으니 이를 보시면 될 것 같습니다:
* 영상을 모두 다 보시는 것을 적극 권합니다만 때론 동영상을 보는 것이 개념을 빨리 잡거나 정리할 때 글보다 불편하고 느린 경우가 있죠. 그래서 제가 글로 요약을 해보았습니다.
** 설명의 편의를 위해 몇몇 슬라이드가 빼거나 순서 등이 바꾸었다는 것을 미리 밝혀둡니다.
Outline
개요는 다음과 같습니다. 첫번째 부분에서는 딥러닝이 잘 나가는 이유를 살펴보고 이어 상당히 실전적인 팁들을 소개하고 있습니다. 저는 개인적으로 두번째 부분이 정말 도움이 되었습니다.
- Trends of Deep Learning (DL)
- Scale is driving DL progress
- Rise of end-to-end learning
- When to and when not to use "End-to-End" learning
- Machine Learning (ML) Strategy (very practical advice)
- How to manage train/dev/test data set and bias/variance
- Basic recipe for ML
- Defining a human level performance of each application is very useful
- Scale is driving DL progress
- Rise of end-to-end learning
- When to and when not to use "End-to-End" learning
- How to manage train/dev/test data set and bias/variance
- Basic recipe for ML
- Defining a human level performance of each application is very useful
바쁘신 분들을 위한 3줄 요약
Abstract
(from NIPS 2016 website)
How do you get deep learning to work in your business, product, or scientific study? The rise of highly scalable deep learning techniques is changing how you can best approach AI problems. This includes how you define your train/dev/test split, how you organize your data, how you should think through your search among promising model architectures, and even how you might develop new AI-enabled products. In this tutorial, you’ll learn about the emerging best practices in this nascent area. You’ll come away able to better organize your and your team’s work when developing deep learning applications.
Trend #1
Q) 왜 하필 지금 Deep Learning (DL)이 뜨고 있나?
A) 양적 팽창이 큰 기여를 하고 있다.

빨간 선이 SVM이나 logistic regression 같은 전통적 학습 알고리즘의 성능을 나타냅니다. 데이터의 양이 어떤 임계점을 넘는 순간 더 이상 성능이 증가하지 않는 것을 볼 수 있습니다.
빅데이터의 시대가 오면서 데이터의 양적 팽창으로 인한 잉여 정보를 성능의 향상으로 끌어올릴 수 있는 방법이 부재했던 전통적인 알고리즘과는 달리, Neural Nets은 이를 바탕으로 좀 더 커다란 모델을 학습시키는 것으로 새로운 시대를 여는데 성공했죠.
여전히 적은 데이터 수만이 있는 상황에서는 위의 그래프의 순위가 얼마나 열심히 feature를 디자인하느냐 혹은 특정 문제를 얼마나 깊히 이해하고 공부했느냐에 따라 변동이 있긴 합니다만, 대다수의 경우 큰 모델을 학습시킬 방법과 많은 데이터만 있다면 문제를 해결할 수 있는 시대가 온 것입니다.
Trend #2
이에 이어 같이 따라오는 것이 end-to-end learning입니다.

이전까지는 기계 학습이 다룰 수 있는 output 값이라 해봐야 분류를 위해 Class를 나타내는 정수나 확률을 나타내는 실수 정도뿐이었습니다. 분야가 발전함에 따라 최근 나오는 학습 방법들은 좀 더 다양하고 복잡한 output을 내놓을 수 있게 되었죠. 쉬운 예로 image captioning이나 generation 혹은 WaveNet과 같이 오디오를 생성하는 모델 등이 있겠습니다.
Feature extraction 등의 여러 모듈로 이루어져있는 기존의 방법들과는 달리 입력을 받아 모든 일을 Neural Nets이 처리하여 결과를 출력하기 때문에 "end-to-end"라고 불립니다. 이런 모델이 너무 black-box 같아서 비판을 받기도 하지만 어찌 되었든 기존의 모델이 잘 해결하지 못하는 문제를 너무나도 잘 해결하기 때문에 큰 반향을 일으키고 있죠 (예, 음성 인식):

Andrew 교수님이 이런 특징? 때문에 생긴 해프닝을 소개해주시는데 상당히 재미있으면서도 좀 씁쓸하기도 합니다.
"이런 end-to-end 얘기를 해주면 꽤나 많은 반발을 마주하게 되는데, 한 때 스탠포드 대학에서 결국 음소(phonemes)란 것은 언어학자들의 환상이 아니냐는 말을 했다가 실제 언어학자로부터 엄청나게 비난을 받은 적이 있다. 뭐 그런데 지금 와서 생각해보면....내가 이긴 것 아닌가? (웃음)"
이렇게 보면 뭔가 end-to-end learning이 모든 문제에 두루두루 적용이 가능한 만능 열쇠처럼 생각할 수도 있겠지만 사실 이 부분에서 Andrew 교수님이 방점을 두는 부분은 좀 더 조심스럽게 end-to-end 방식을 적용해야한다는 것입니다.
즉, end-to-end learning 방식이 많은 문제에 대해 잘 통하기도 하지만 반대로 그렇지 않은 경우도 종종 볼 수 있다는 것이죠.
그러면서 예를 든 것이 자동주행프로그램이었는데요 물론 이 역시도 아예 안 된다는 것이 아니라 자기가 봤을 때는 end-to-end learning처럼 순수히 Neural nets이 모든 것을 알아서 해줄 것이라 생각하며 시도해서는 답이 없다고 말하는 쪽에 가까웠습니다.
이어 딥러닝 방식이 적절한 데이터만 주어진다면 거의 항상 X에서 Y로 가는 함수를 학습할 수 있는 것은 맞지만 그렇다고 해서 그게 문제를 해결하는데 꼭 좋은 방법이냐는 것에는 동의할 수 없다고 덧붙였습니다.
End-to-End works only when you have enough (x,y) data to learn function of needed level of complexity.이 부분은 정말 깊히 생각할 필요가 있는 것 같습니다. 실제 상황에 적용을 할 때 무작정 DL이 모든 것을 해결해줄 것이라 믿으면 안 된다는 것은 모두 동의하실 것입니다. 이렇게 정리해서 얘기하기도 사실 좀 우스워 보입니다만 실제 정책이나 큰 프로젝트들이 진행되는 것을 보면 꼭 그렇지도 않아보입니다... -_-;;
같은 맥락에서 보면 "음소"에 관한 얘기는 Andrew 교수님의 말과 오히려 약간 상충되는 것은 아닌가 싶은 생각도 들었는데요. 저는 음소라는 개념 자체도 꽤나 공들여 세운 하나의 특징인만큼 병행하여 사용한다면 더욱 성능을 향상시킬 수 있지 않을까 하고 생각해봤습니다.
Machine Learning Strategy
개인적으로 이 부분이 이 강의의 정수라고 생각합니다. 교수님이 쉬운 도식으로 현장에 바로 적용할 수 있는 가이드라인을 제시해주시는데 팁들이 매우 실용적입니다.
연구를 하다보면 다음과 같은 상황에 빠질 때가 있죠
- 돌아가는 AI 시스템을 만들긴 했는데 더 성능을 향상시키려면 무엇을 어디부터 시작해야할지 막막할 때,
- 제대로 된 전략이 있다면 몇 달의 시간 낭비를 없앨 수 있다는 것은 알지만 내가 제대로 하고 있는 것인지 모르겠을 때,
딱 이럴 때 도움이 될 수 있게 어떤 "기준점" 혹은 "표준화 된 틀"이 존재한다면 참~좋을텐데 ...
요걸 앤드류 교수님이 딱 도식으로 만들어주셨습니다:
요걸 앤드류 교수님이 딱 도식으로 만들어주셨습니다:
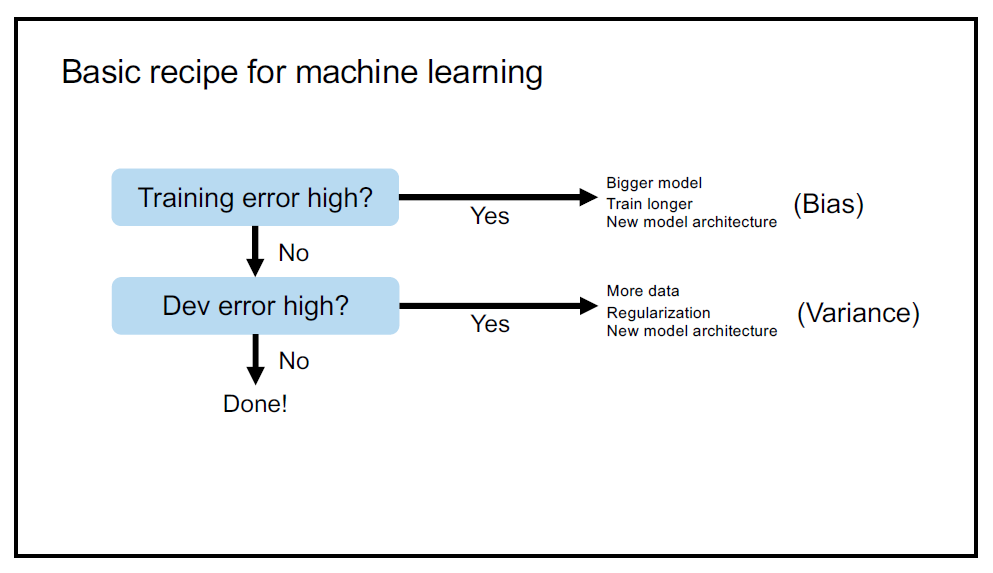
정리해보면 다음과 같습니다.
Training error is high: model이 내놓는 결과와 실제 데이터의 괴리 즉, bias가 크다는 소리입니다. 그럼 다음 방법을 시도해봅시다:
- train longer,
- use bigger model
- or adopt a new one.
Dev error is high: 데이터 간의 variance가 크네요, 그럼 이렇게 해봅시다:
- gather more data,
- try regularization
- or use a new model architecture.

어때요 참 쉽죠?
하나 주의해야할 것이 있는데요, 전통적인 의미에서 bias and variance 라 하면 underfitting과 overfitting 사이에서 regularization을 사용해서 trade-off를 하는 것을 얘기하지만, 여기서 Andrew 교수님이 사용하는 bias and variance는 기존의 교과서 정의와는 조금 다르죠. 쉬운 설명과 이해를 위해 비슷한 개념의 단어를 차용하였다고 합니다.
이런 관점 때문에 예전에는 bias와 variance가 서로의 장단 사이에서 줄다리기를 할 수 밖에 없는 게임이었다면 어떤 면에서는 지금은 좀 더 그 사이를 유연하게 떼어놓을 수 있게 되었습니다.
그러니까 좀 더 큰 모델을 사용하는 것으로 bias를 줄이고 variance는 좀 더 많은 데이터를 사용하는 것으로 극복을 할 수 있다는 것이죠.
이처럼 기존의 방법들과는 달리 DL을 이용하면 눈에 보이는 길이 최소한 두 가지는 있기 때문에 문제를 해결하는데 좀 더 쉬운 느낌을 받을 수 있던 것도 DL이 발전한 이유 중 하나라고 합니다 (절대 그렇게 해서 성공하는게 쉽다고는 않했.....).
Use Human Level Error as a Reference
그런데 이렇게 어떤 error 값이 나왔을 때 그 값이 큰 지 작은 지를 얘기하려면 일단 기준이 필요하죠. 이 기준으로 human level error를 사용해야한다는 것이 교수님의 주장입니다. 좀 더 효율적인 연구를 위해서는 이 human level performance를 알아내는 것이 언제나 최우선적으로 해결되야 한다고 강조하는군요.
예를 들어 다음과 같이 DL을 이용하여 사람 수준의 음성 인식 시스템을 만들고자 한다고 생각해봅시다. 보통 연구를 할 때 train, dev(val), test 이렇게 세 개의 군으로 데이터를 나누고 시작하곤 합니다. 그러면 자연스래 그 사이에 error 값들이 나오는데요:

각각의 error 값의 차가 bias and variance로 명명되어 있는 것을 보실 수 있습니다. 예를 들어 human level error가 주어지지 않았을 때 다음과 같은 값을 얻었다고 해봅시다:
- Train error : 8%
- Dev error : 10%
만약 제가 human level error가 1% 정도라는 것을 알려주면, 문제의 핵심이 bias를 해결하는 것에 있다는 것을 쉽게 알 수 있습니다. 반대로 human level error가 7.5%라면 갑자기 쟁점이 variance 해결로 바뀌는 것을 보실 수 있습니다.
이렇듯 앞으로 연구를 진행할 방향을 알려주기 때문에 human level performance를 알아내는 것은 매우 중요합니다.

Data Crisis
이외에도 데이터를 사용하면서 필연적으로 따라오는 문제가 있습니다. 빅데이터 시대라 하더라도 비슷하거나 일반적인 데이터는 많지만 내가 원하는 연구에 꼭 맞는 데이터는 얻기 힘든 경우가 많습니다.
우리가 자동차 후면거울에 넣을 음성 인식 장치를 개발한다고 해봅시다. 일반적인 대화가 녹음된 데이터는 50,000시간 정도 있지만 "자동차 안"에서 이루어진 대화는 약 10시간 분량만 가지고 있습니다. 이럴 때는 어떻게 데이터를 나눠서 모델을 학습시켜야할까요?
다음과 같이 데이터를 나눠서 학습하려고 하는 것이 제일 안 좋은 방식이라 할 수 있습니다.

이렇게 나누게 되면 dev과 test 데이터의 distribution들이 서로 매우 다르게 되기 때문에 수 개월동안 때려박아 dev 데이터에 대한 성능을 최적화하기 위해 노력하다가 정작 test에서는 원하는만큼 성능을 보여주지 못 하는 경우가 생길 수 있습니다.
그래서 다음과 같이 체계적으로 접근하는 방식이 필요합니다:


위 도식만 잘 염두에 두고 있어도 많은 삽질 시간을 절약할 수 있을 것 같네요.
A few remaining remarks
모델의 성능이 아직 한참 낮을 때는 성능을 높힐 여지도 충분하고 취할 수 있는 행동도 다양합니다. 기본적으로 앞서 소개했던 방식들을 시도해볼 수 있겠죠:
- error analysis
- estimate bias/variance
- etc.
- Label is made by human (so the limit lies here)
- Maybe because human level error is close to the optimal error (Bayes error, theoretical limit)
그럼 이후에는 딱히 방법이 없는 것일까요? 쉽지는 않지만 그 때부터는 모델이 사람보다 잘 못하는 문제들을 모아서 (마치 오답노트처럼) 그 부분에 대한 약점을 집중적으로 학습시키는 방법 등이 사용된다고 합니다.
마지막으로 딥러닝 분야에서 잘 나갈수 있는? 방법 두 가지를 짧게 조언해주며 발표를 마치는데요 역시 정석에 가까운 애기입니다만 마침 제 블로그 대문과 Andrew 교수님의 조언이 비슷한 것이 기뻐 소개해봅니다;
practice, practice, practice and do the dirty work
(read a lot of papers and try to replicate the results).
which happen to exactly match with my headline of blog. I am glad that he and I share a similar point of view:
READ A LOT, THINK IN PICTURES, CODE IT, VISUALIZE MORE!
그럼 이 것으로 정리를 마치겠습니다. 도움이 되셨으면 좋겠네요! :) 정리 끄읕.
댓글 없음:
댓글 쓰기